I looked into this more and was able to get some more info and come up with a (less-than-ideal) workaround. We still need to come up with an actual solution to this. I’m going to post what I’ve found so far in detail, in hopes that this will help lead us a permanent solution.
I’ll go into what I found, but first, here is the workaround for those interested. It is modifying ActiveRecord itself. DISCLAIMER: I have no idea what sort of implications this change has, use at your own risk
Workaround: comment out this line in active record. For me that meant going to /home/vagrant/.rvm/gems/ruby-2.4.1/gems/activerecord-5.1.4/lib/active_record/railtie.rb and commenting out ActiveRecord::Base.clear_reloadable_connections! around line 153.
What I’ve found so far: I was able to get some excellent help from a user named dminuoso on #RubyOnRails (freenode). He suggested using debug locks to get some more information. This meant adding config.middleware.insert_before Rack::Sendfile, ActionDispatch::DebugLocks to config/environments/development.rb, restarting the server, reproducing the issue, and then pointing my browser to <server>/rails/locks.
This showed a thread locking two other threads (in some cases it was 3 others) with a traceback. This traceback showed the clear_reloadable_connections! method above, which led me to the workaround.
As far as what is creating that lock, it was suggested any code using lock! or AR::Base#connection_pool could be causing this. I see two instances in Dynflow one two that are using connection_pool, but I couldn’t confirm they are causing this lock.
Doing some more debugging, I found this SQL statement executing right before the lock
SELECT "katello_events"."object_id" FROM
"katello_events" WHERE "katello_events"."in_progress" = $1 ORDER BY "katello_events"."created_at"
ASC LIMIT $2
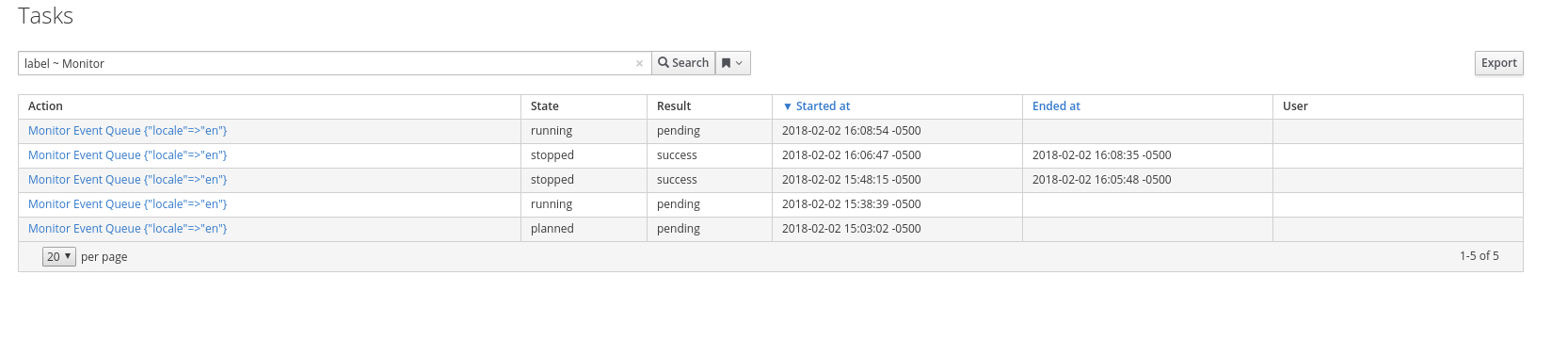
which would indicate the katello event queue is to blame, and goes along with @ehelms’s theory in a previous comment.
Some devs have had luck commenting out the event queue as well. Its not foolproof in my experience, probably because it can restart on its own.
There is an issue in rails that possibly could be related, where they suggest to use ActiveSupport::Dependencies.interlock.permit_concurrent_loads to fix deadlocks. I was suggested this on #RubyOnRails as well.
Hopefully this helps us pinpoint the exact issue further, let me know if you have any questions about what I’ve posted. Lets beat this pesky issue