
Thank you very much @Og_Maciel for your detailed reply. I think I speak for the entire community when I say we greatly appreciate the effort Red Hat QE has been putting into improving our test coverage.
As for the technical detail of which identifier to use, I think we very rarely rename tests unless we change the test contents as well. So perhaps in that case it would be good that someone from QE actually sees that test named test_X doesn’t exist anymore and can decide if the polarion id should now just be mapped to the new name test_Y, if the test case in polarion needs to also change as well, or catch the fact that we mistakenly removed a useful test case and we should bring it back.
3 Likes
Really appreciate the long reply, thanks @Og_Maciel!
Just my 2 cents, how about a YAML file which matches Polarion IDs to test cases? It’s still too cumbersome IMO, if someone has to do this matching manually.
You mentioned you can’t rely on test_names alone, however wouldn’t it be possible to add automatic UUID to Polarion ID matching for everything we have, and a config file (YAML or whatever), which lists the exceptions to that rule? I would expect the list to be manually populated with test cases when they change the name but the contents haven’t changed so much, as in the ‘long email’ example you mentioned.
Thanks for the suggestion @dLobatog, I appreciate your input! I feel that there are several ways we could come up with a solution for this problem and I apologize for not having all the details and “behind the scenes” for how Polarion works and, more importantly, its (many) limitations.
Right now I could get the list of UUIDs that are part of the PRs that were pending and generate a “map”. Regardless of its format, this map would allow us to identify all the 460 tests that were merged upstream and that have an entry into Polarion. We still don’t have tooling that would then be able to take the JUNIT files generated by the upstream automation, look up each test against the map and then update Polarion with the test result (i.e. passed, failed, skipped), but I’m sure we can get it done.
What about all the other existing automated tests that are not part of the 460? Since there is no counterpart for them in Polarion, there is nothing to map against, so as of right now we can’t track them there. We could create a mechanism that would automatically create a Polation test case for these tests but Polarion is a bit more rigid in the sense that there are many attributes and fields that are required and without them, this process would not work. Some of these required attributes are: test type (functional, unit, integration, etc), is it a critical/high/medium/low severity, are they for upstream only, what are all the steps required and what the assumptions for each one of them, is there a setup required, is it a positive or negative test, and the list goes on and on. The combination of these fields and attributes allows us to establish some goals and release readiness plans that could for example say: All critical integration tests must pass against a given build but a 85% pass rate for high and medium severity test cases is acceptable for GA.
For our existing automated tests written in Python, all this information lives in the docstrings for each test (or module or class of tests) and we have a tool that can parse this information and: update Polarion if some of these fields have changed and update test results every time a test is executed.
If you’re curious as to how this is done, here is test case level example and here’s a module level example.
As others have said, the in depth discussion is appreciated.
test type (functional, unit, integration, etc)
I could see explicit markers in our code for this since it’s a common concept that’s IMHO useful to everyone using the tests.
is it a critical/high/medium/low severity
IMHO this is irrelevant for us. Tests must pass before a PR is merged. They should never break after being merged. It could happen with plugins, but any failure should be treated as an issue because it blocks merging new PRs.
This is IMHO the biggest benefits of getting tests in our testsuite: they block merges so pass rates become a binary yes/no.
We also apply smoke tests before we promote to nightly. There we can gate even further because there we install actual systems and run tests. Finding the regression should be much easier if you have at most the changes of a single day and we block further updates to nightly. With sufficient automated tests published nightlies should always be production ready.
are they for upstream only
This one should live downstream IMHO. What if others like ATIX want to ignore tests for their products, then we’ll end up with huge ignore lists. Tests could also become relevant for downstream and it’s weird to need an upstream PR to remove the blacklist.
what are all the steps required and what the assumptions for each one of them, is there a setup required
I could see such metadata being useful, especially if we can allow actual integration tests with compute resources if they are configured. I know pytest is very flexible in this regard, don’t know about our rails testing.
is it a positive or negative test
Can you explain what you mean by this?
I’m very surprised docstrings are used instead of marks (or custom marks) as they are IMHO the most powerful features of pytest.
In a previous job I used @pytest.mark.integration('backend-1') and I could run all integration tests against that backend with pytest -m integration=backend=1. You can replace backend-1 here with vmware or ovirt. Tests can have multiple marks, for example if you want to see how it behaves with both vmware and ovirt configured. Other examples can be plugin=ansible for example.
I miss pytest.
Yup, this is exactly why we started this process and we have roughly 740 hammer cli tests that could be beneficial here too.
I started typing my own definition for these types of tests but then I came across this definition which I think does a good job:
"Positive testing determines that your application works as expected. If an error is encountered during positive testing, the test fails.
Negative testing ensures that your application can gracefully handle invalid input or unexpected user behavior. For example, if a user tries to type a letter in a numeric field, the correct behavior in this case would be to display the “Incorrect data type, please enter a number” message. The purpose of negative testing is to detect such situations and prevent applications from crashing. Also, negative testing helps you improve the quality of your application and find its weak points.
The core difference between positive testing and negative testing is that throwing an exception is not an unexpected event in the latter. When you perform negative testing, exceptions are expected – they indicate that the application handles improper user behavior correctly."
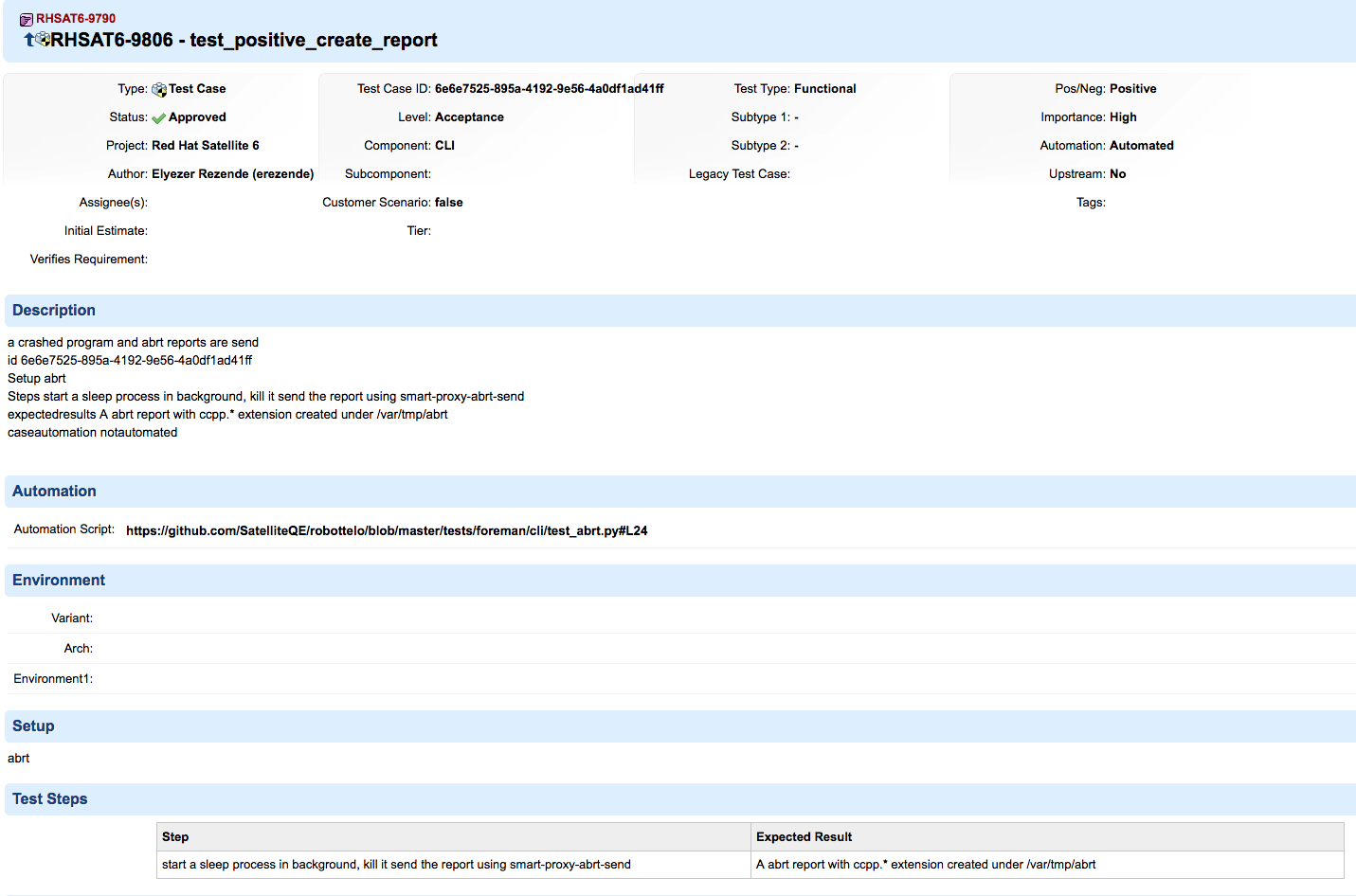
The idea for the docstring “tokens” are not to control which tests will be executed. For that we do rely on pytest marks. For example, we have a mark called ‘stubbed’ which indicates that the test case exists but has not yet been implemented. The idea here is to be able to read this information and then generate a formal test case that contains all fields and values required to consider it as valid. Remember the example I provided before? Here’s what that gets imported into Polarion (see screenshot)
As others said, I thank you for the explanation and I can only confirm that what you guys do is appreciated. It’s not an easy job of Quality Engineer, nobody told you it’s gonna be easy 
Now, technically I don’t see much difference between maintaining UUIDs in a codebase and maintaining an extra mapping file. Creating a tool that will list all tests which are missing mapping should not be difficult. I have to admit that UUIDs are more convenient because you can grep them easily and it’s “write and forget”, but it is technically still possible to create a (HTML) cross reference (e.g. with github.com URLs pointing to test filenames with line numbers).
It is important to realize that we are not bound only to test names, strings which appear after test "this is a test name" keyword. There is a context available in Minitest and this context can get you much more information:
- namespaces (contexts) the test was executed in
- ruby source filename
- ruby source line
- test result
- test duration
I think including Ruby source line is a bad idea, but namespace of a test and/or Ruby source filename might be a good idea to take into consideration. We rarely rename tests, we sometimes rename filenames. Therefore I suggest to ditch “static tree analysis” and create minitest hooks which can get you more info.
I think the key for success of the mapping approach would be automation and testing, those are disciplines you can teach us about. There can be a code which will compare mapping file at the end of the suite and print out all missing mappings. This could lead to a test failure actually if mapping is not correct.
Instead of tagging tests as functional, unit or integration, I’d rather see us fixing our test codebase by splitting them into meaningful directories because we already have that concept (Rails) but it is IMHO not correct - our tests are basically unit or functional tests. We have I think zero real integration tests.
I got the “lucky” card tagged as “the asshole who blocked UUIDs”, but I want to assure you my intentions were pure and I raised this topic hoping for the best. There was probably someone else raising this if I did not do it. Honestly, I thought we’d agreed on UUIDs and as much as I would prefer external mapping I’d be fine with them. I understand that this is sometimes bitter pill to swallow, I had to close many of my own PRs myself.
3 Likes
Not at all. I think that the real issue was that I did not know what the right process was to do this and I spoke to folks directly instead of turning it into a public discussion. It’s not that I was trying to circumvent processes; just that I didn’t know about it. ![]()
2 Likes
If there’s places we can improve the documentation of our processes, or even the signposting to the docs, then I want to hear about it. If you got bitten by this, so will others ![]()
1 Like
Has this been done? if so, it would be good to clean up the tests in Foreman that still have the test_attributes helper preceding them.