Problem:
After a daily scheduled task runs to publish new versions of content-views i’m getting Pool echaustion and SSL errors
Expected outcome:
No errors in log
Foreman and Proxy versions:
2.3.3 - all latest updates
Foreman and Proxy plugin versions:
Distribution and version:
CentOS 7
Other relevant data:
Not sure if it’s related, but i noticed this happening after fixing candlepin certs:
Relevant logs:
This is the first error:
[I|app|4e4b1ce7] Started GET “/rhsm/consumers/eb5d92cd-1366-4aba-9acf-f7cc08158acc/certificates/serials” for 127.0.0.1 at 2021-03-16 13:33:39 +0000
[I|app|4e4b1ce7] Processing by Katello::Api::Rhsm::CandlepinProxiesController#serials as JSON
[I|app|4e4b1ce7] Parameters: {“id”=>“eb5d92cd-1366-4aba-9acf-f7cc08158acc”}
[E|kat|4e4b1ce7] ActiveRecord::ConnectionTimeoutError: could not obtain a connection from the pool within 5.000 seconds (waited 5.000 seconds); all pooled con
nections were in use
4e4b1ce7 | /opt/theforeman/tfm/root/usr/share/gems/gems/activerecord-6.0.3.4/lib/active_record/connection_adapters/abstract/connection_pool.rb:221:in `block in wait_poll’
Looked into Telegraf data, and memory appears to stay stable, using about 20gb of 32gb - at least when it happened this morning. Looking at historical data, everything appears normal at times when this happens.
It happened again now at 13:00-ish, but that was likely due to load spiking to 10-ish ( where normal is 1-2, up to 3 under high load times during daytime ) but i think i’ve found the cause for that: CentOS 8 stream sync plan - just hadn’t deleted it yet, will see if its the same case tomorrow.
But I’ll definitely keep an eye on resource usage.
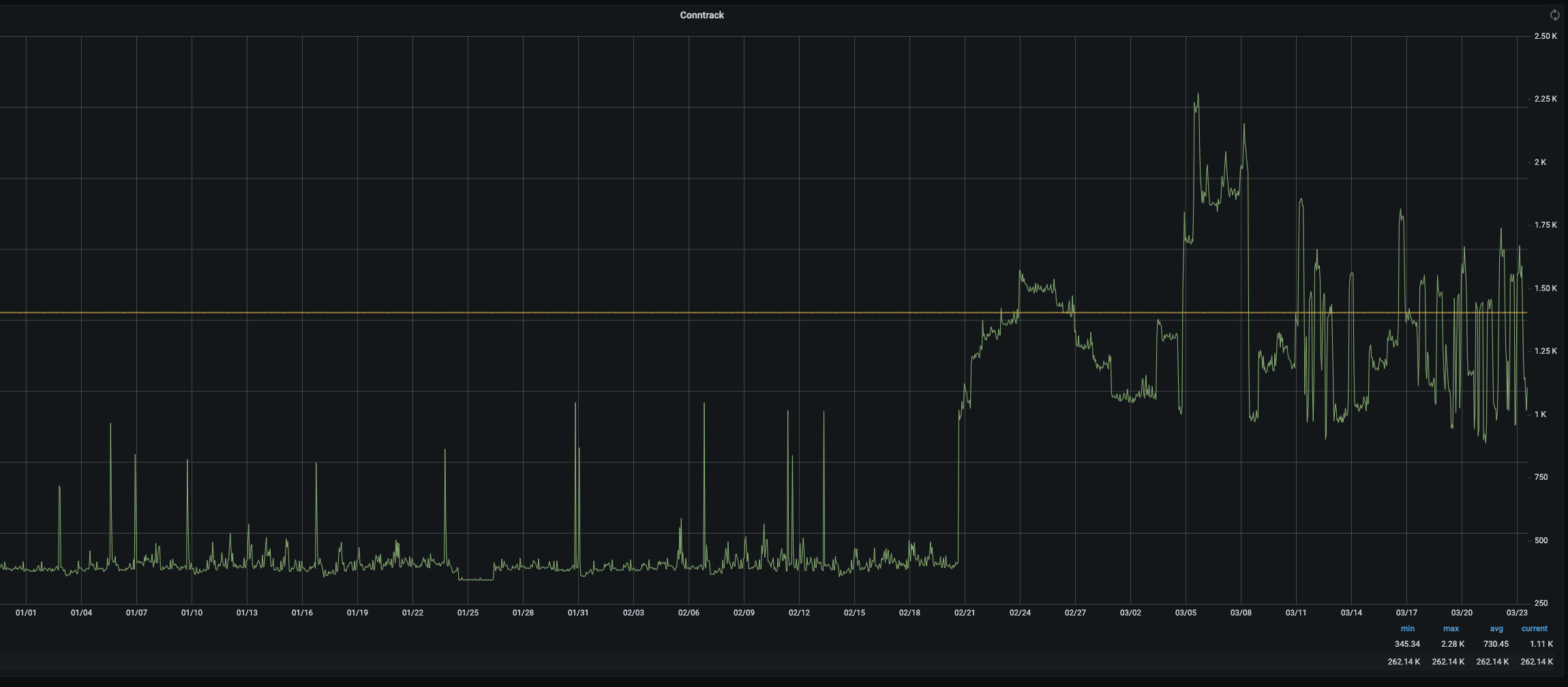
This is interesting though - Conntrack sees a huge bump in connections after 20th Feb - It’s nowhere near the max, but it’s still a definitive change in behaviour with no changes being made to Foreman itself at that time.
Though looking at the timing (16:00), that corresponds to my OracleLinux 7 sync plan.
Gonna do some more testing when i have time
(ignore the yellow line on the graph)