The deployment of a containerized architecture inside Kubernetes requires supporting a transitional approach to more closely match upgrades to and allow targeted movement of services into a container based deployment.
The goal is to enable a platform with core services and the ability to bring secondary services online along with any requires backend services in a modular way. This implies an ability to be able to package secondary services independently for deployment. This leads to the following deployment goals:
Ability to deploy core service(s) with customization
Ability to deploy secondary services independently
Ability to deploy to a cluster with a minimal cluster permission set
Ability to deploy to Kubernetes and community Kubernetes distributions
Ability to deploy to external Kubernetes
Support all-in-one deployments
Design
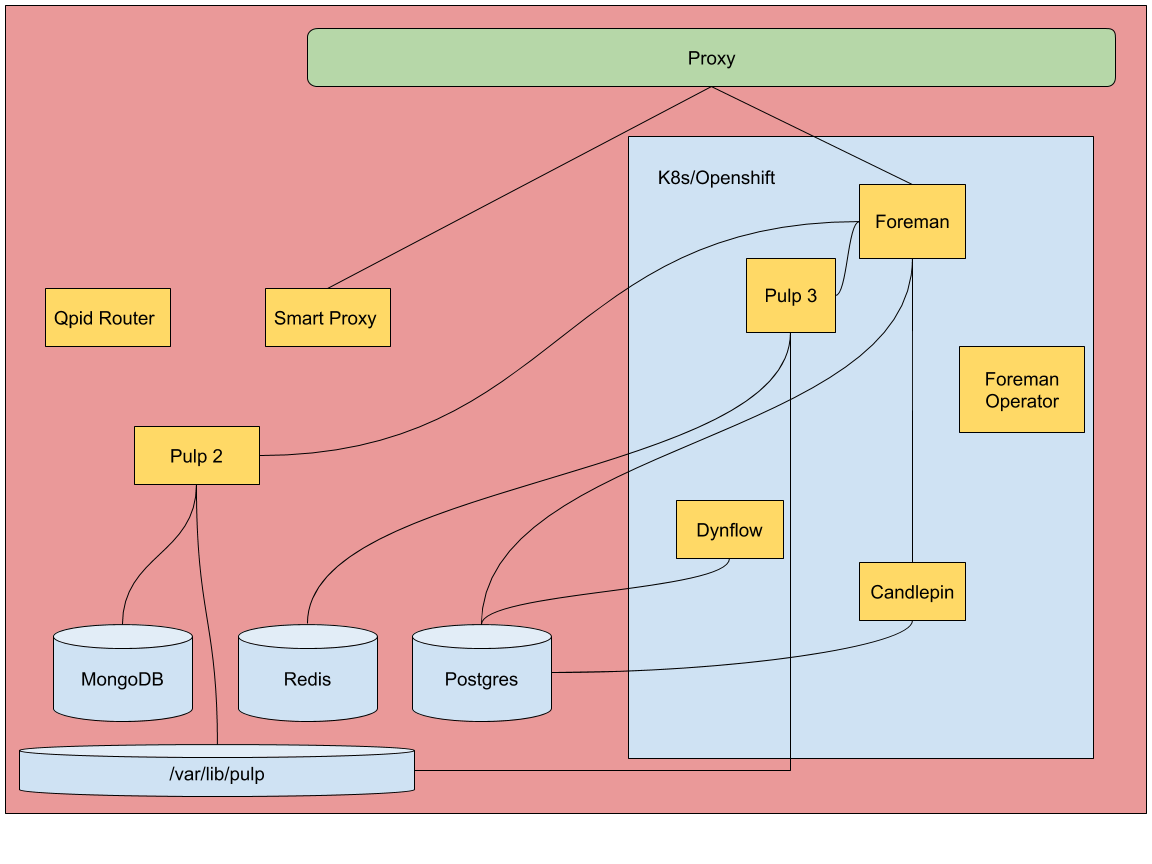
The design is to use an Operator to manage the state of an instance of Foreman running on Kubernetes. The Operator would be based upon the ansible-operator allowing the capture of deployment and remediation tasks in Ansible code. The Operator will use a Custom Resource Definition (CRD) to define what a Foreman deployment will look like. Likely, other operators will be used for managing dependent services of sufficient complexity (e.g. Pulp or Smart proxy). For example, with a warning that this layout is proposed at present, you may want a Foreman server with Katello and Remote Execution and two dynflow workers:
The architecture proposal is designed to match the upgrade scenario in order to support a stepped approach to introducing containerized services and provide parity with existing deployments, see Upgrades for what that upgrade process looks like. This architecture relies on putting services into a Kubernetes environment targeting stateless services at the outset. The databases would begin by living outside of the Kubernetes environment with an option to run them inside Kubernetes.
The base deployment would put a Kubernetes on the same box as all services to provide the single box experience as the base case for users. Optionally, services could be deployed to an existing Kubernetes environment and connected back to a host(s) running databases.
What happens when I transition the plugin from false to true? Is hte assumption that all the sidecar images are there, and the operator knows to now “activate” it?
Effectively that is the idea. This where the operator gains us some benefits. By setting say REX to true, the reconciliation loop inside the operator would call the Ansible code with the new data. The code would be written in such a way to deploy any required additional containers, deployments, etc. to bring a particular plugin online within the environment. This could include, but is not limited to, activities such as spinning up required secondary services or re-deploying the Foreman pod in a way to avoid disruption of services where possible.
I like the fact that the DBs and pulp storage are running outside of k8s as running those benefits the least from the whole thing and also brings the biggest risks.
Regarding the use of operators, the only concern I would have is that ansible-oprators are pretty new project in pre-alpha stage: are the release cycles of this project in sync with the roadmap for this effort? What would be the other options, in case ansible-operators turned out as a dead-end (just to be sure there is some safety net).
I think this makes upgrading the easiest and allows for a more transitional approach. I know that there are also those that, even with the advancements in handling databases inside Kubernetes, worry about having a persistent data store ran inside of Kubernetes. This would also provide for fully external databases to feel the same. I do think we would support running databases inside the cluster as well.
You are correct that the project is quite new. I’ve been working with the development team for ansible-operator as part of my testing an implementation with it for Foreman. Given I had written much of the deployment tooling in Ansible, this became a natural fit. I cannot say I know what the release cycle for the project is yet. This is being heavily discussed. What I can tell you is that there are plans to make this a first class operator, to build it into the operator-sdk and support it alongside the operator-sdk. Having worked with the team testing some of the pull requests, and implemented some early stage CI for them, I feel confident that we would not be picking a dead end. The concept is simple enough that even if it were, we could easily migrate to another option or continue to use this pattern. You can think of it as a container that is constantly running an Ansible playbook to reconcile the state of the application based upon a custom resource definition.
The alternative to the ansible-operator is to write an operator in Go. I was avoiding this option to avoid developers having to learn another programming language. The overhead to contribute by writing Ansible seemed significantly lower than using Go to me.
@ehelms: Do you mind clarifying what tasks the operator would take care of? Would it build the containers?Install plugins? Or just create (primitive) resources inside the cluster? How would it do it’s job? With the spec you provided, what would you implement in the ansible modules?
Have you considered creating an operator in plain ruby? This should work as well. I hear that people shift from using helm charts for deployments towards ansible. Where do you see the advantages?
The general idea of the operator is to put the operation of the application into software. A form of automating things that a human might previously have done. Initially the operator would focus on deploying the application, ensuring the state of the application and making any changes based upon the configuration or change in configuration of a custom resource definition. The operator would create all of the Kubernetes resources (e.g. persistent volume claims, secrets, deployments, etc.). Then, based on specification ensure that those resources exist. For example, if you told your resource I want 2 Foreman pods and 3 dynflow pods, the operator would ensure that state exists.
The Operator is for deployment and operation of the application and would not be building containers. However, depending on the plugin strategy the operator would handle orchestrating the installation of said plugins.
The Operator is first a concept. The operator-sdk that CoreOS built is designed to build a Go-based Operator. The ansible-operator project (being integrated into the operator-sdk) is designed to allow writing your operator in Ansible. There is also a Helm operator in the works to allow writing Helm and deploying it to help avoid the Tiller permissions issues. In the case of the Ansible operator, it works by every X seconds, running a playbook. That playbook will do whatever you tell it to. In our case, the playbook applies a set of roles. Those roles use Kubernetes modules to create Kubernetes resources and ensure state today. All that is to say, there is no module writing to be done on our part. The idea of the ansible-operator is to let folks write an operator with Ansible and potentially re-use existing roles instead of learning Go. The ansible-operator itself is written using the operator-sdk and handles all of the Go and tasks that need to be done (e.g. the run loop, setting owner references inside Kube).
I think writing it in Ruby would be a lot more work, duplicate what the operator-sdk is attempting to provide, and force us to learn and care about all the operational concepts, hooking into CRDs, etc. that the operator-sdk is designed to handle for us. I have found the Ansible easy to write so far. Both due to just writing Ansible being fairly simple, but also because most of it is defining what look like native K8s resources.