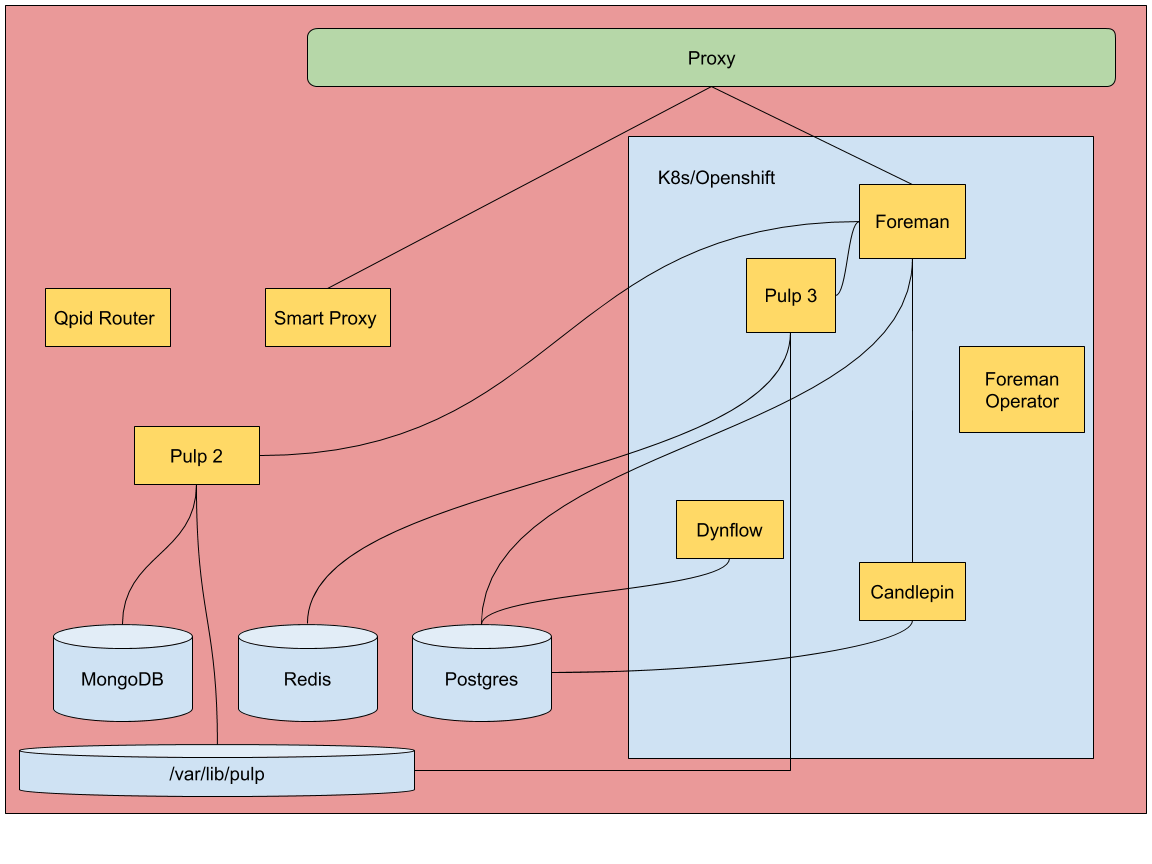
The intent is to ensure that users can move from a traditional to containerized deployment with as little impact to their infrastructure as possible and without leaving behind any users to continue to grow the community. In order to facilitate this, upgrades should operate with the following in mind:
All data must transition to be usable by new deployment model
Remote datastores and databases should continue to work
Clients must continue to work against new deployment
Open Questions on Requirements
Should migration be limited to the same code version running in both deployments?
For example, should we only allow migration from Foreman traditional to Foreman containers
What is the parallel path support time frame? In other words, for how long do we have two deployment models and support them in parallel?
This affects how long we give users a chance to migrate to the new platform and how much support cost we incur maintaining both
Data Sources
Current deployments rely on multiple databases and file data stores for storage of critical information required to operate. These databases and data stores can range from 10s of GB to multiple TBs of data. These are the data stores that must be migrated with size ranges based on known user deployments:
Postgres database
/var/lib/pgsql/data
1 GB - 25 GB
MongoDB database
/var/lib/mongodb
5 GB - 300 GB
Pulp content store
/var/lib/pulp
/etc/puppetlabs/code/environments
100 MB - 3 TB
Certificates for client communication
/etc/pki/katello
/usr/share/foreman
/etc/foreman-proxy
….
< 30 MB
SCAP reports
/var/lib/foreman-proxy/openscap/
1 - 100 MB
Strategy
The aim is to take the existing server, expand the memory and CPU footprint to support running K8s on it and migrate services from the host to the containerized version of them. Databases and data stores would continue to live on the host and be connected to services inside K8s or volume mounted where necessary. This strategy allows for the transition of services to containers over time based on project and stability as well as bringing online new services in a container native way. A proxy will be required to route services properly to the K8s based services to provide a seamless hostname as we do today to keep clients and infrastructure working as expected. Early candidates for transition:
Foreman
Dynflow
Pulp 2 & 3
Candlepin
Stateless services
Pros
Single host deployment, re-uses existing host
Allows slow transition of services
All stakeholders can more slowly learn and become comfortable with containers
New containerized services can be brought online in a container native way
Keeps qpid-router running on host which is not currently solved in K8s
Cons
Potentially requires a host with more RAM and CPU for users
Installing K8s on existing host with other services may not be optimal
Will require some proxying to ensure services route to the correct place
Will need hybrid upgrade and management tooling, likely wrapping existing installer in Ansible
I would be big advocate for this approach - as it sounds like the safest way of transition and isolating whether any issue is caused by some regression in a new release, or is related to the new deployment strategy. It would also allow better evaluation of the k8s approach while the traditional approach would still be available.
I assume this is not limited only to Satellite, but it means the same for any Foreman (with or without Katello) deployment.
I think it should be determined by the confidence level we have in the new deployment: we should keep the traditional approach until we can honestly tell every single user that they are safe to transition. This also means that if we’re not aware of any issues at some point, we can start dropping the Foreman-classic deployments. It’s hard to guess at this point on how many releases it would be.
It’s probably not cost effective maintaining 2 solutions, as long as one solution can support everything that the second does and allows more. So as I mentioned, as long as we’re confident about the k8s solution, we should start dropping the classic approach. In that case, we should be open about the plan that the current approach will be dropped at some point.
I’m missing a section about the upgrades after transition to k8s, ideally how it relates to the foreman-maintain upgrade workflow and what would be the strategy for those upgrades, to make sure we don’t end up “now what” after we get to k8s deployments.
Very much like the idea of being able to rollback and start the “traditional” services. Does this really require much more RAM if we make an assumption that parallel execution would not be supported (either k8s or traditional)?
That is one of the documents I did not send along yet as an RFC but is in the PR I mentioned. I put this under ‘Day 2 Operations’ to try to keep the focus on upgrade procedure for traditional. If you feel I need to add it here to complete the RFC and conversation I am more than happy to move it in.
I think the extra RAM is required to run Kubernetes. I don’t think we can get away with a whole hog upgrade to containers for users. The transitional approach seems to be the approach that gets us there over time with the least disruption.
I’ve been asking myself that. The answer is that it is likely a good choice for continued centralization of operational tasks and would provide a singular interface for transition. Other than that, I have not given enough thought to what tooling we need to support externally to provide users. I’d appreciate any thinking in this area based on the RFCs so far.