We recently moved our foreman to version 3.1 and puppetserver 6.
We also started with Rocky Linux 8 to replace CentOS 7 in the future.
Building a Rocky Linux vm on one of our clusters is working perfectly fine.
However using the same kickstart files and building the vm on another cluster is not working fine.
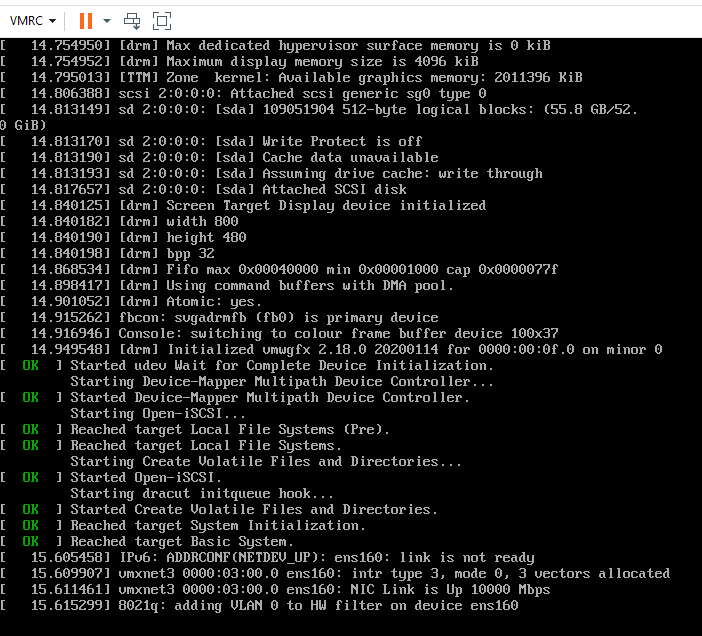
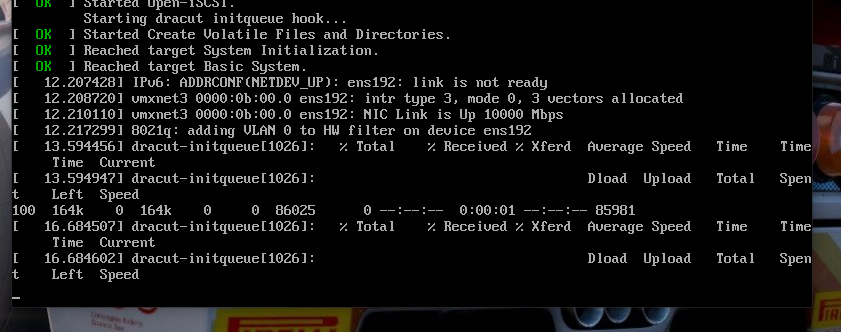
The build process gets stuck in this step (see below screenshot) and doesn’t move forward even after 30min wait.
No error comes in the console about what the actual issue or timeout could be.
It’s certainly not firewall related as building other vm’s in the same subnet with CentOS is working fine.
I suspected an hardware or vsphere issue with Rocky 8 so I changed ESXi version to use the same build of 6.7U3P5 on the cluster with the issue.
This didn’t resolve it.
We also tried configuring different network adapters like VMNET3 or E1000 or tried different SCSI controllers all without it making any difference.
So in short all settings are the same the only difference is the actual cluster hardware that is not identical. ESXi version was not identical before but is now.
Any ideas about extra logging we can turn on, places to look for the issue ?
As we ran out of ideas ourselves.
We checked the smart-proxies and couldn’t find any error.
We checked the foreman production.log but couldn’t find any issue.
We also checked /var/log/messages but also no issue in there.
If I understand the last line correctly, you have configured the network interface to be tagged with vlan 0. That’s not allowed. VLAN tag 0 is reserved. If the interface is untagged, don’t configure it as virtual nic. Otherwise, configure the correct vlan tag.
Also the ESXi doesn’t expect one for this subnet.
Further more a machine that is building properly also displays this message but continues straight away.
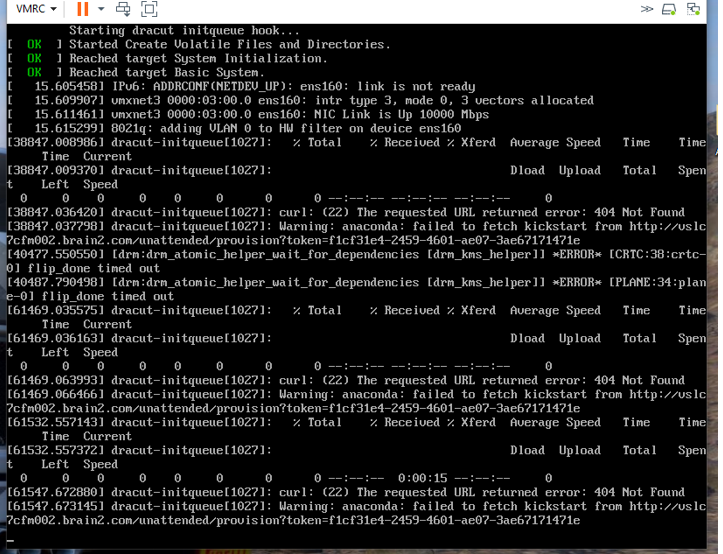
It looks like the 404 is eventually coming on the shell after the token is expired ?
It was expired anyway this morning.
I tried to build again with a new provisioning token, I checked if the URL exists and yes it does.
I checked wether it is accessible from a host in the same subnet as the one we are building in, this also works.
It doesn’t look like a DNS issue as there is no message about that either.
But at this point it is still totally unclear why it can’t fetch the kickstart from our foreman host.
As before it is able to fetch the kernel and initrd from the same foreman host in a different folder (boot).
After your host drops into dracut shell, can you test the network? You should have things like bash, ping, curl etc - full initramdisk of Anaconda.
If the VM does not drop into shell, you need to add rd.shell=1 I think (unsure about the name google it out). Just add this to the kernel command line (PXELinux template or whatever template you use).
No that’s the thing, in the console if I ALT + TAB there is nothing I can try.
No shell is available.
Neither when the build seems stuck of after the token has expired.
I will try to add the “rd.shell=1”.
Also I was thinking it might be the proxy to the Windows active directory causing issues, I still had 1.24 running. But the other DC has the same one without issues.
Tried to upgrade the proxy to 3.1 but with that one I experiences issues like DNS pointer records creation failing.
I moved to 3.0 and this one works fine, but no improvement for the original issue.
Somehow while attempting to build again in 2022 I managed to get the shell already without modifying anything.
It’s clear now that the network connection itself is the issue.
DHCP didn’t provide an IP to vm in this stage.
But somehow it did get one earlier to download the kickstart files.
We tried to restart the DHCP server service on the windows host, this didn’t resolve the issue.
I can try to perform a reboot maybe as well but it’s still stange that in the first step it does get an IP from DHCP to download the kernel and initrd.
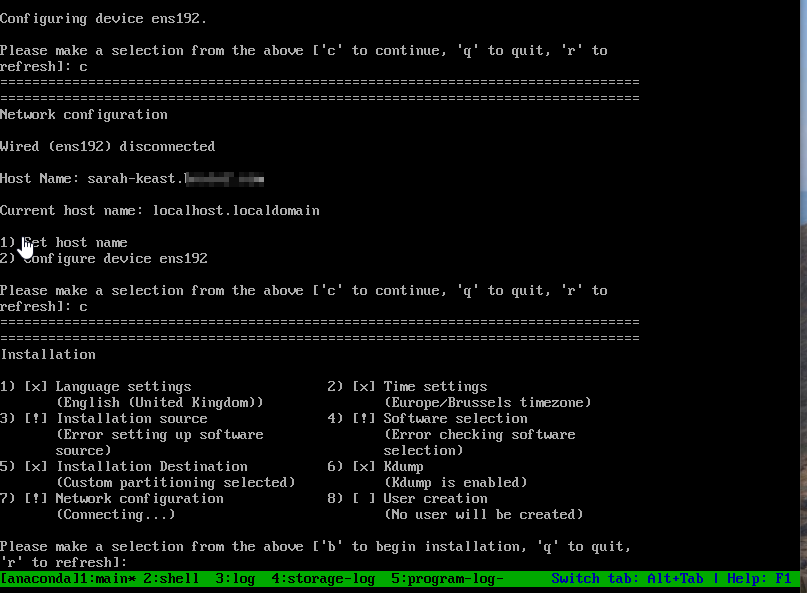
If we manually configure step 7 (network configuration) in main it has network.
Ok we finally found the solution after doing some additional wireshark captures on the domain controller.
We suspected that the untagged subnets on the same cable, which for this location is the case because of legacy, could be the culprit.
So after tagging the subnets on network level with the proper vlan id, the issue is now solved.
Somehow CentOS 7 and older never has an issue with this.