Just a general question: is it normal that foreman is “really slow”? I mean the HW I run it on is quite old (Xeon X5550 @ 2.67GHz), but still, I have given it 20 GB RAM and 6 cores…
There’s almost nothing in it yet (one hypervisor and 3 to 5 VMs).
After VM boot, it takes several minutes before the foreman web page becomes responsive; when trying to reboot the VM, stopping foreman seems to take 1-2 minutes.
Running foreman-installer to add the plugin-remote-execution stuff took several minutes as well.
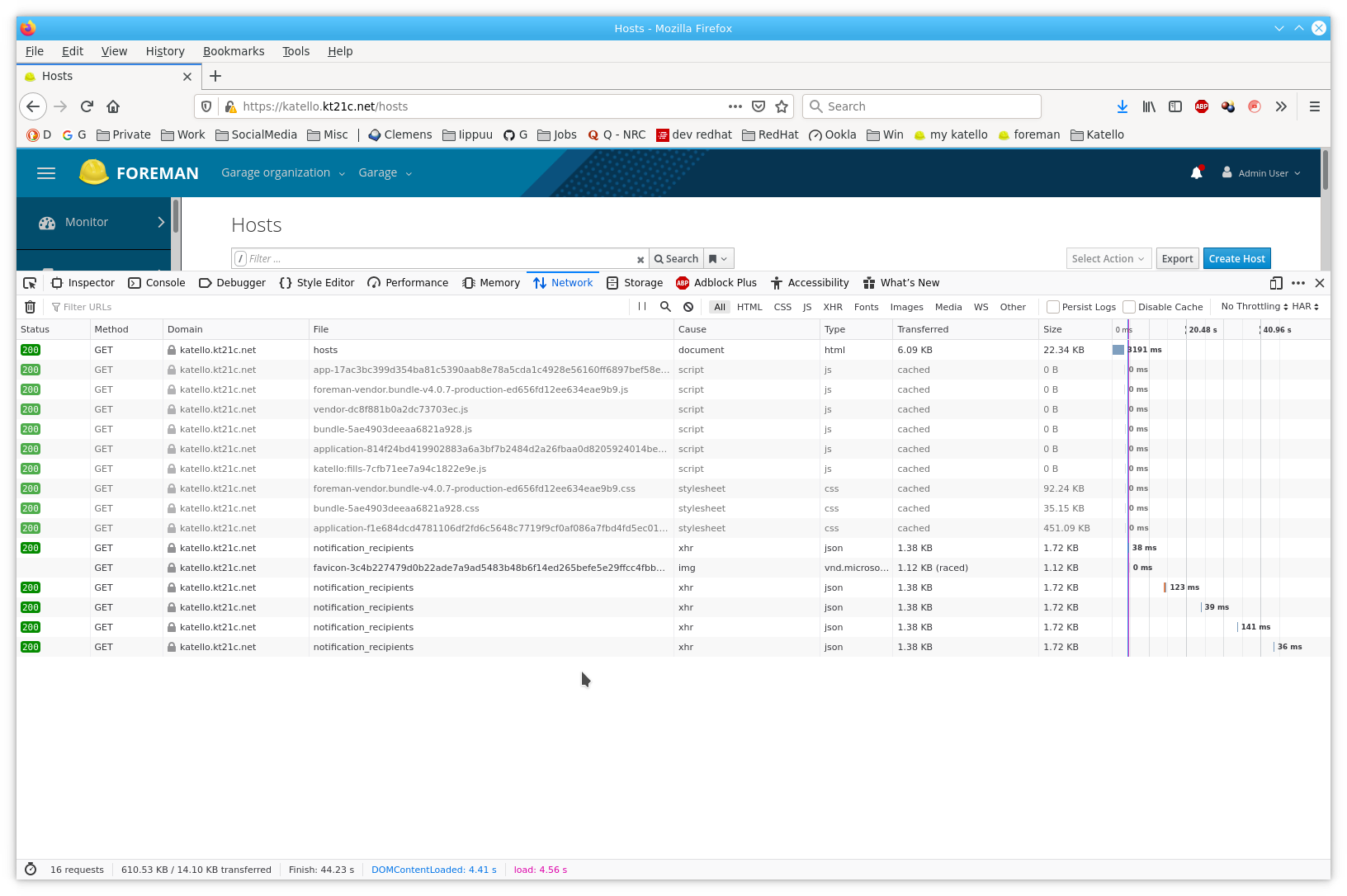
Navigating inside foreman, it might take several seconds before the new page displays ![]()
For Partitition Tables and Provisioning Templates, 2-3 seconds, for “All Hosts” 6 seconds. (The “is host on or not display” I have already disabled).
foreman-maintain service restart takes almost two minutes:
[root@katello ~]# time foreman-maintain service restart
Running Restart Services
================================================================================
Check if command is run as root user: [OK]
--------------------------------------------------------------------------------
Restart applicable services:
Stopping the following service(s):
rh-mongodb34-mongod, rh-redis5-redis, postgresql, pulpcore-api, pulpcore-content, pulpcore-resource-manager, qdrouterd, qpidd, rh-redis5-redis, squid, pulp_celerybeat, pulp_resource_manager, pulp_streamer, pulp_workers, pulpcore-worker@*, smart_proxy_dynflow_core, tomcat, dynflow-sidekiq@orchestrator, httpd, puppetserver, dynflow-sidekiq@worker, dynflow-sidekiq@worker-hosts-queue, foreman-proxy
/ All services stopped
Starting the following service(s):
rh-mongodb34-mongod, rh-redis5-redis, postgresql, pulpcore-api, pulpcore-content, pulpcore-resource-manager, qdrouterd, qpidd, rh-redis5-redis, squid, pulp_celerybeat, pulp_resource_manager, pulp_streamer, pulp_workers, pulpcore-worker@*, smart_proxy_dynflow_core, tomcat, dynflow-sidekiq@orchestrator, httpd, puppetserver, dynflow-sidekiq@worker, dynflow-sidekiq@worker-hosts-queue, foreman-proxy
\ All services started [OK]
--------------------------------------------------------------------------------
real 1m55.697s
user 0m7.871s
sys 0m3.729s
[root@katello ~]#
Is ruby on rails (celery?) generally that slow, or is there perhaps some problem with the setup or my VM?
top and sar do not show significant load; looks like it was all the time only one single ruby process 99% CPU…