
ok, i started to use the default configuration from the puppet modul for foreman (workers=0, threads_min=0, threads_max=16)
in parallel i try different puma configurations (workers, threads_min, threads_max). it seems that these have an effect on memory consumption.
my experience so far:
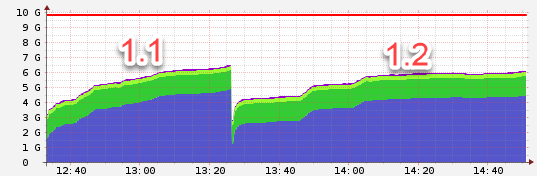
Nodes 1:
1.1 used the defaults, 1.2 worker:2, threads_min: 8, threads_max:16
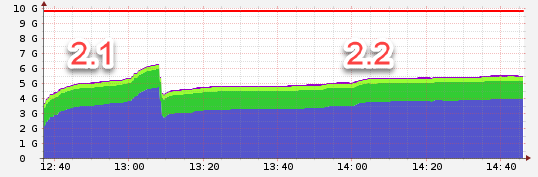
Node 2:
2.1 used the defaults, 2.2 worker: 4, threads_min: 4, threads_max: 8
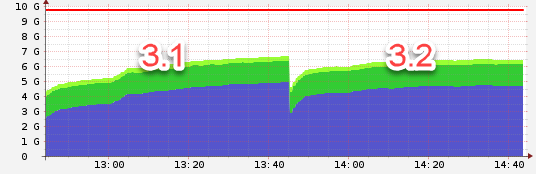
Node 3:
3.1 used the defaults, 3.2 worker: 4, threads_min: 8, threads_max: 16
all have in common that the threads_min is configured to != 0. i will keep watching the different setups.