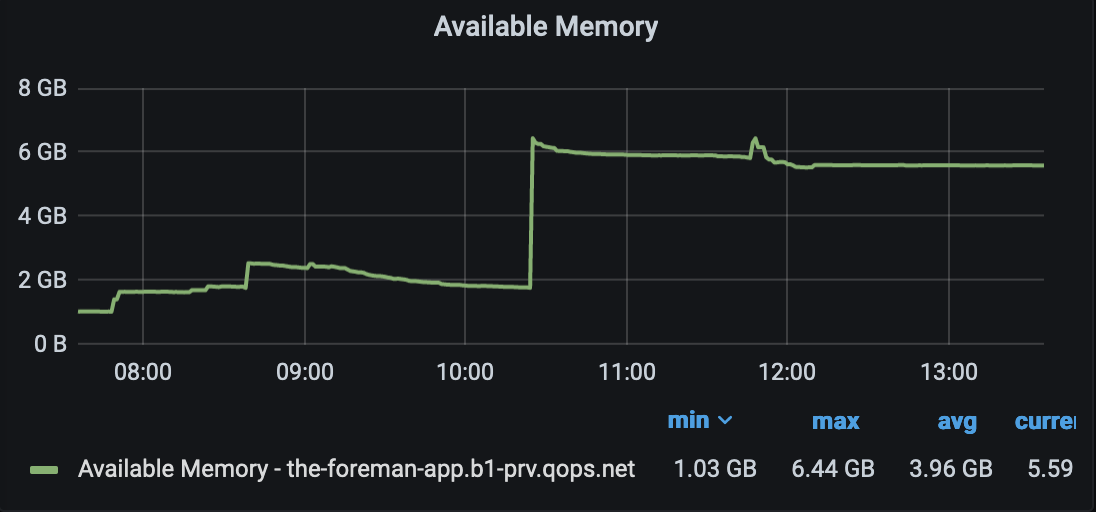
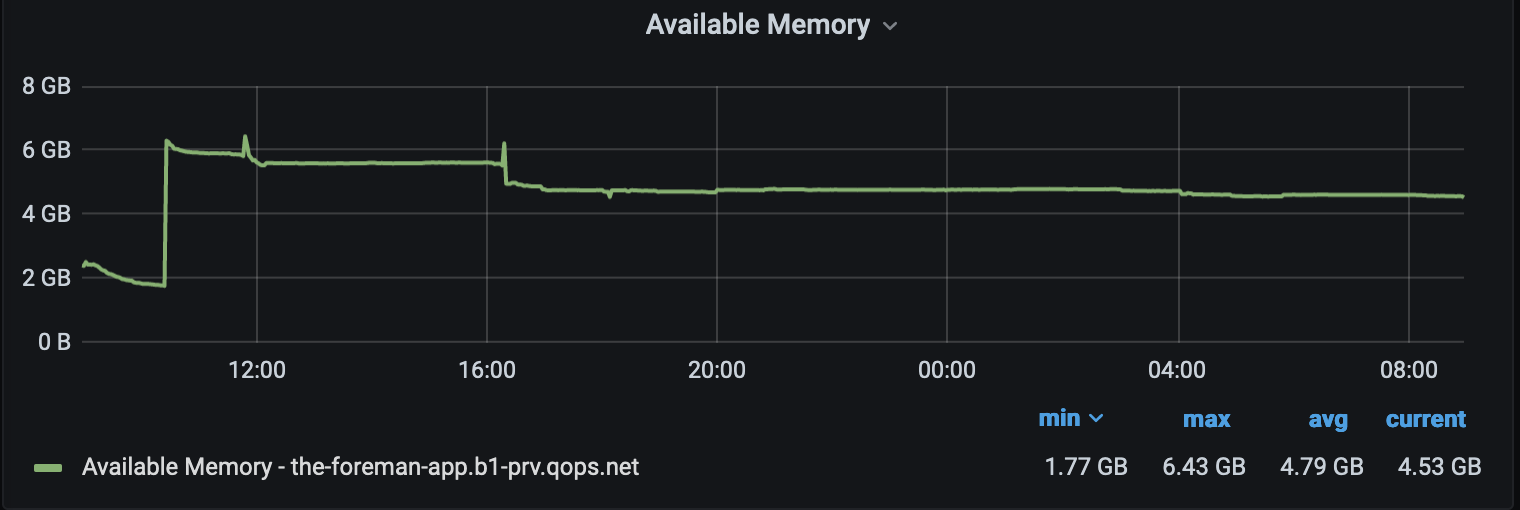
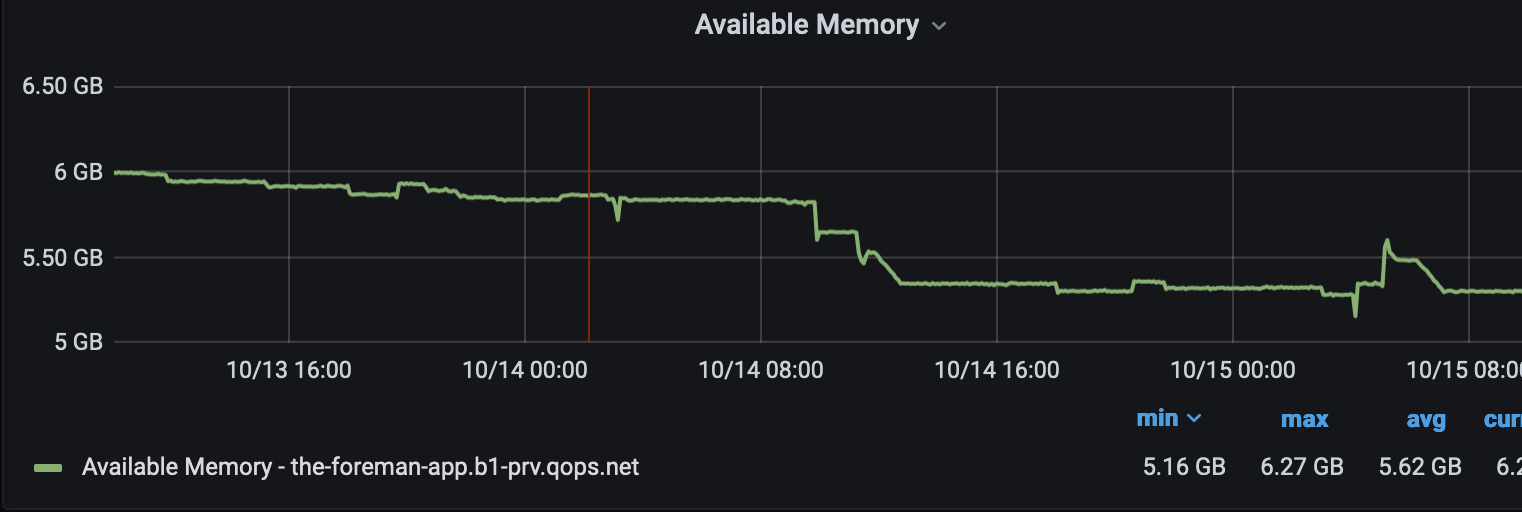
This thread: Foreman install 2.5, HTTP: attempt to connect to 127.0.0.1:3000 (127.0.0.1) failed started getting lost on these issues so creating a new thread to report on performance issues we are seeing with Foreman 2.5.3. After some troubles getting Foreman 2.5.3 running (see linked thread) we’ve seen dramatic memory usage compared to 2.2. We’ve upped the memory on a couple of VMs running Foreman in various environments without much change. I’ve attached some performance graphs on what we are seeing. We have a server running the default cluster mode, one running single mode, and one running single mode with the max/min threads set to 15. In all cases we see the gradual loss of available memory to the point the boxes start swapping, and restarting the container recovers the memory, which then continues it’s gradual decline.
In the first attachement,
The yellow (orange?) line is the box that was restarted from 2.5 to 2.2 for about a day, then re-started to 2.5.3 with single mode, and you can see that as soon as 2.5.3 was started (using puma instead of passenger) the memory slowly decreases over time.
The blueish line is a box that is just running the default configuration, we upped it’s memory as well but it just creeps down until it’s restarted.
The Green line was a box that was running the min/max threads set to 15 and single mode, but we ran into an issue where if we hit the box with more than 6 threads at a time doing a VM sync, it would spin up 130 http threads, and all of them would time out eventually and nothing would get synced. If I run just 6 threads against that box it would work mostly, but I’d still get 12 timeouts and about 30+ http threads, vs the two other boxes that would sit at 24 http threads and could process all the api calls (this was all done via api calls)
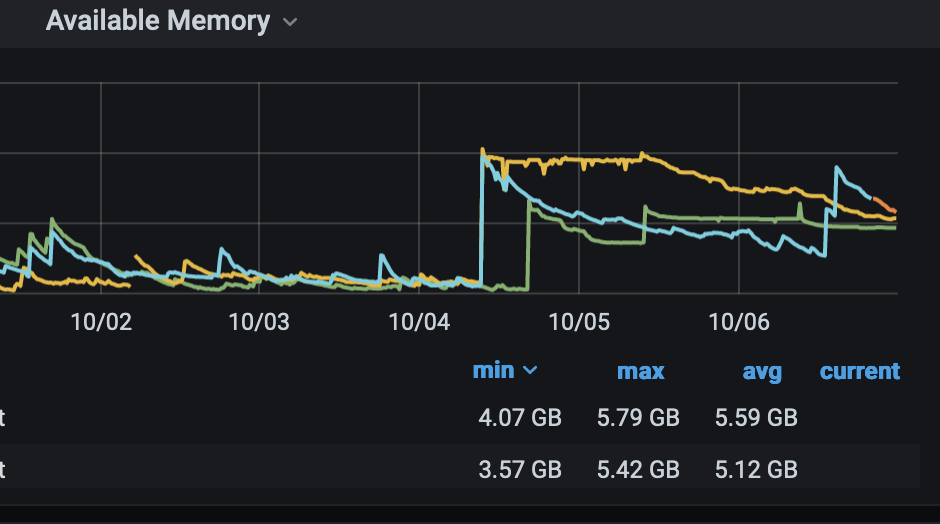
The second attachments
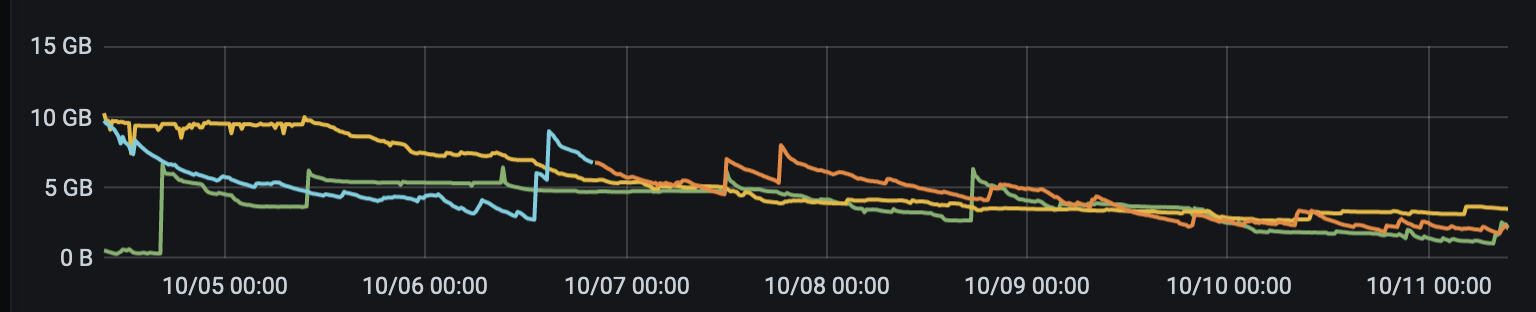
shows the last 7 days, and you can see how they just keep loosing memory over time. We never saw this with Foreman 2.2 using passenger.
I’ve included my proxypass settings as thats what I’ve been messing with, as well as my two Foreman ENV settings:
ProxyPass / http://127.0.0.1:3000/ retry=1 acquire=3000 timeout=600 Keepalive=On
ProxyPassReverse / http://127.0.0.1:3000/
I had to include the keepalive and timeout as building into EC2 to run the finish script would timeout before it could finish. I am unsure on the retry setting.
To run in single mode I specify:
export FOREMAN_ENV=production
export FOREMAN_BIND=tcp://0.0.0.0:3000
export FOREMAN_PUMA_WORKERS=0
Before running. And to specify the workers min/max threads
export FOREMAN_PUMA_THREADS_MIN=15
export FOREMAN_PUMA_THREADS_MAX=15