Problem
\We regularly call the sync VMs against all the computes in the compute list, as we move VMs around quite a bit, and in the previous version we ran (2.2) if a compute in the compute list happened to no longer exist (but it’s DNS record still existed for whatever reason) this would, at worst, throw some errors in the log and the the whole application would move on with it’s day. We would call the api with about 15 threads at a time and chug through the whole list of hundreds of computes in about 10 to 20 seconds regardless of how many dead records we may have.
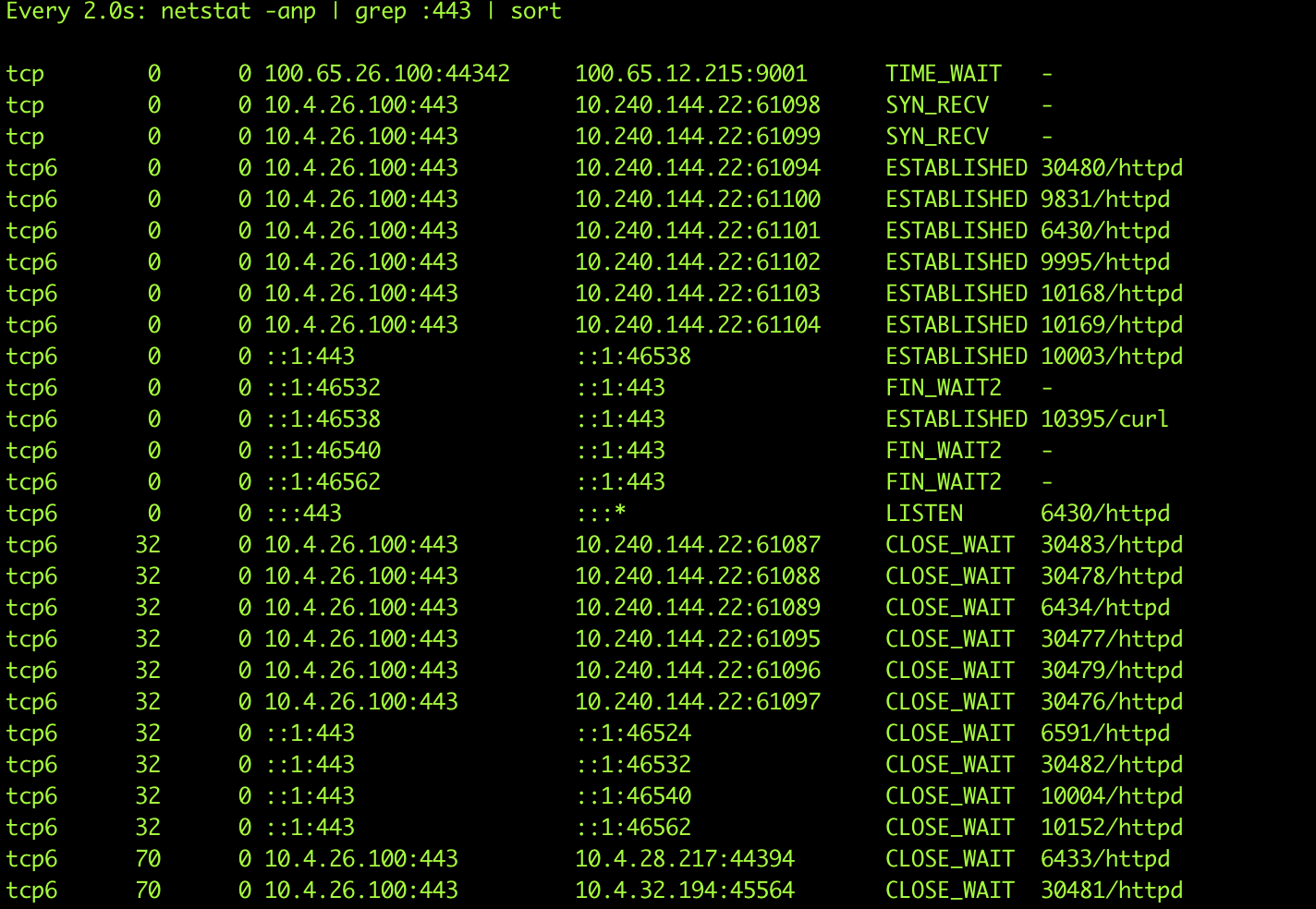
Updating to 2.5.3 and later 2.5.4 when the sync vm is called on just one bad compute record, the entire application locks up, and no further threads can run. In Netstat I see a lot of CLOSE_WAIT and any additional requests (from the UI or API) just hang and eventually the requests timeout, but the app never really recovers. The same can happen if I try to edit the compute_resource as well.
Expected outcome:
Like 2.2, if just a single record happens to be bad, the entire application shouldn’t lock up and prevent the processing of any other requests.
Foreman and Proxy versions:
2.5.4,
Foreman and Proxy plugin versions:
Distribution and version:
Other relevant data:
The symptoms seem very similar to another thread I started, where foreman seems to do the same locked up behavior, but in that case it happens after some amount of puppet reports come in, in that the whole application locks up, is unusable and I have to restart all the proccesses to get it to recover. This is just a very easy way to reproduce it. I can reproduce by just clicking the sync VM button in the UI, I don’t even have to go through the API to get it to lock up.