Hello all. Ive been using Foreman for a good 7-8 years and have deployed small instances of it at various shops. I’ve come across a new project that wants to replace their Salt API UI with Foreman (thanks to Broadcom buyout of VMware). They have around 90,000 nodes, globally. I have already implemented Foreman for their Linux patching (about 50% of above hosts), with Katello/Pulp.
However, now I need to work on replacing jobs/tasks for the same number of nodes. Out of the 90k nodes, they are split at about 5-7k nodes per saltmaster. Ill be able to utilize this to my advantage, but my main concern is how Foreman will handle these requests/jobs. So the focus here is Dynflow and Sidekiq. Just starting the planning phases of this architecture, I have some questions:
How many jobs and/or tasks can Foreman handle? Lets assume that I will have the following setup:
2 Foreman servers - Foreman UI/API and Foreman ENC/Reports. PostgresQL Active/Passive backend on a separate server. Should I also have a 3rd Foreman server to just handle jobs/tasks?
Originally I was going to set those up with memcache, but after researching more, it appears I want to setup redis for this, to keep them all in sync?
I imagine that there would be times where they are going to need to run something against all 90k nodes. How will Foreman/Dynflow/Sidekiq handle something like that? If we have 18-20 saltmasters, all running a Foreman Salt/Proxy, that certainly fixes any sort of bottleneck there, but I just cant comprehend how to setup the architecture for this on the job/task running/caching side of things.
Any ideas, thoughts or help would be greatly appreciated. Yes, I have read all the blog posts, links and sites about Foreman at scale. Very helpful!
I don’t think we have some best practices guide apart from the tuning guide, but you should be able to scale the backend services independently on the rest.
Without any data to back this claim up, I can just say that many smaller jobs should perform better than a single gigantic job due to the way it’s implemented. For details I’ll shamelessly point you to one of my older posts Help to find the bottleneck in foreman-task / remote execution - #2 by aruzicka in the hopes you haven’t seen that one yet.
That is extremely hard to quantify as not all jobs/tasks are equal and it depends on a lot of factors. I would expect a standard deployment to be able to handle a job on ~8000 hosts (as in a single job with 8k hosts in it) within ~15 minutes. Of course, this is more of an educated guess rather than anything else so ymmv.
Thank you very much for your replies, and link (which, no I have not seen yet). I also agree, I do not suggest running against 90k hosts all at once, and the chances of that happening are almost impossible.
I guess what my plan is, is to just prepare and scale it the best I can. Unleash it into production and continue to scale out if we have issues.
Now Im wondering if I can just spin up 3-4 foreman instances, with all services on each, and just put a load balancer in between them with memcache or redis behind them. Although, I dont think that would prevent the use case of a single user logging in, and kicking off a run of 30,000 jobs. The single Foreman server they end up on would still be the sole server running those jobs. So it seems moreso that I need the balancing to be on the Dynflow/Sidekiq side of things. Perhaps, I can detach Dynflow/Sidekiq from Foreman itself, and somehow clusters servers running those services so regardless of where a user initiates jobs from, it would always be load balanced against multiple Dynflow/Sidekiq instances.
After further discussions, it sounds like they often run salt queries against all hosts at once. It takes them about 10-15 minutes to start getting some results back. 60-90 mins to finish, and some never return at all.
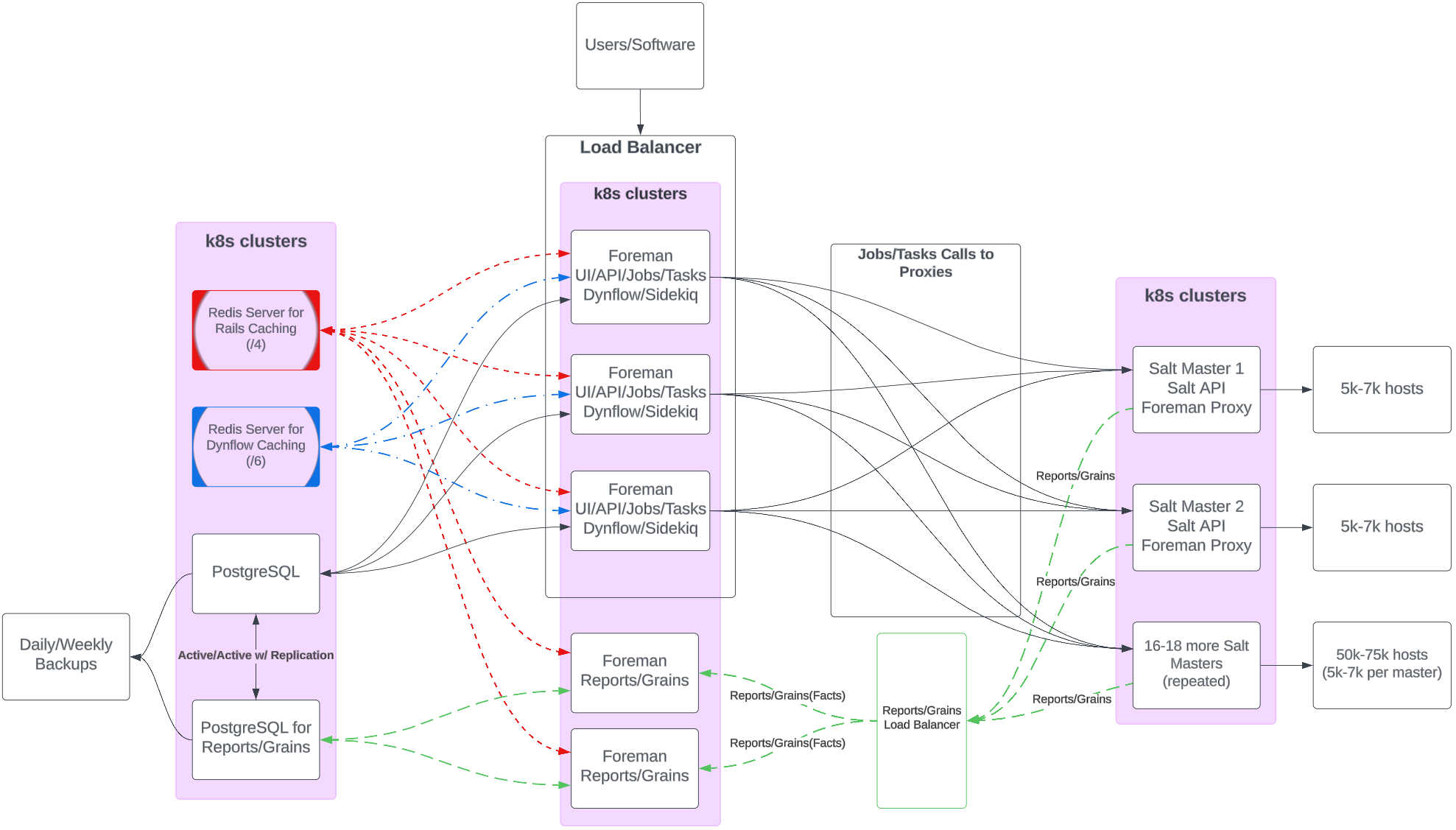
Here is my initial architectural chart. Im not sure I need to type much to explain it, as the diagram itself should explain it. I dont generally like to ping people, but @aruzicka, maybe @TimoGoebel or @lzap - I have seen your names on many scaling/large scale deployments. Wondering if you had any input?
My two worries of bottlenecks are:
A job being kicked off on 90,000 hosts (this may potentially occur frequently)
The reports and grains (facts) coming back from said jobs
Eventually this will surpass 100k servers, potentially this year.
A couple of more thoughts to myself, as I stare at this.
Im a bit worried about the postgres side. If I have large numbers of reports/grains(facts) coming in to one servers instance, and it needs to replicate to the other server in order for the UI servers to display it, it feels like thats just the same as running everything on a single postgresql server…
Does anyone know how jobs/tasks are handle in relation to salt? If a job is kicked off on say 1000 servers, is there a task created for every single host, and then that request is sent over to the foreman-proxy on the saltmaster? Or is it sent over in blocks of n amount, that the saltmaster than queues up?
HI! Sorry for offtopic comment, but I so impressed by your architecture. Especialy about runnig Foreman in k8s infrastructure.
Can you tell please, do you use custom foreman image and helm chart or some opensource solution?
If it’s not on NDA can you tell more about your case? In the internet there is a huge lack of information about runnig Foreman in k8s.
Thank you in advance!
Honestly, I am not sure lol. We are literally just trying to comprehend how to do all this. There is a really good video about foreman in k8s - https://www.youtube.com/watch?v=mPjUvNAYp1c - but otherwise we are just trying to figure it all out for ourselves. Basically we are just breaking down all parts of foreman and then attempting to containerize the services. The idea being we want to be able to just automatically spin up new containers if and when the foreman production infrastructure needs it.
For now, that is a long ways away. We are just attempting to first replace our vmware (thanks a lot broadcom) Salt Config UI, as the cost will be skyrocketing into the millions. And Ive used Foreman in past shops, but not at this scale. So I think we wont even be really diving deep into the k8s side of things for another 6-9 months. Maybe I will have more then
Just of our curiosity, you have 90000 hosts managed by one Foreman Katello server (+ multiple smart proxies)? Without any HA and Load Balancing of your Foreman server (not Smart Proxy server) ?
We have 2 foreman infrastructures, one for patching (katello) and one for managing salt. Both manage around 90,000 nodes.
The Katello infrastructure runs with a single main foreman server, separate SQL server and 65 proxies.
The Salt infrastructure runs with 11 main foreman servers, 3 handling UI, API and Jobs behind a load balancer. 3 handling grain/fact and report imports behind a load balancer. 2 redis servers, one for UI syncing and one for dynflow syncing, and then a single SQL server. Then 65 proxy servers, one on every saltmaster for grain/fact/report pushing and remote execution to the minions.
Why you decided to split it to two environments - one for content management, second for salt-related stuff and I guess for everything else? Were there any problems with setting up Katello version behind load balancer?
Katello and Salt are 2 very different services and systems. It made sense then to split them out, so we can handle upgrades, debugging, triaging through different teams.
The Katello infrastructure is not behind any load balancers. Single foreman server that pulls down upstream packages, then the proxies that use the main foreman server as a upstream. We may however add a load balancer soon with a secondary foreman server, since even with 24 cores and 128GB of ram, on SSDs, its struggling.