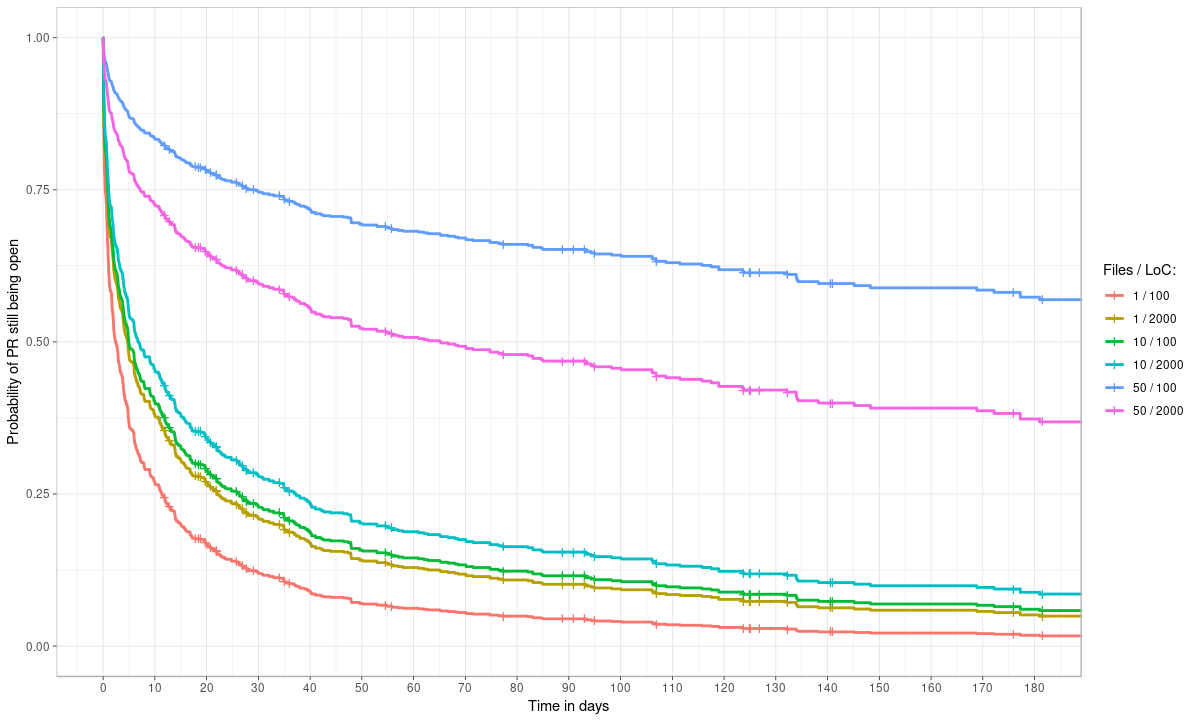
In this post I’m going to dig into some of the data we have on GitHub about how
our community functions. In particular, I’m looking to investigate some of the
issues raised on
Discourse
to help draw some conclusions about how to structure Foreman’s code-and-review
processes.
This is a companion discussion topic for the original entry at https://theforeman.org/2019/03/merge-time-review-complexity.html
Just for fun, I tried a different model for combining LoC and Files, which does make them both significant. Here’s the curve:
And the coefficients:
| Term |
Coefficient |
Confidence (upper) |
Confidence (lower) |
| loc |
0.0170481 |
0.0321533 |
0.0019405 |
| changed_files |
4.0558174 |
5.2075042 |
2.8901381 |
| loc:changed_files |
-0.0009435 |
-0.0006715 |
-0.0012155 |
Note how now LoC doesn’t include 0, so it is significant (to 95% confidence), but still, the magnitude of the Files coefficent is way higher, so I don’t think it changes my conclusions.
Forgot to mention in the post - code and/or model details are, of course, available if anyone wants them.
3 Likes