Hi everyone,
I was recently working on the outofsync_interval and I found it non-intuitive that the expected_report_interval is the sum of reported_origin_interval and default_report_interval (see here) which resolves to outofsync_interval + #{origin.downcase}_interval. I would intuitively expect that #{origin.downcase}_interval would overwrite the outofsync_interval. Is there a reason why it was solved this way?
This scope that is used in the dashboard suggests that the outofsync_interval should actually be overwritten.
(The line might also need some adjustment as it is now possible to add the outofsync_interval as host parameter) .
I’ll try to illustrate that on Puppet example. Puppet usually wakes up every 30 minutes. Then it peforms the run which takes e.g. 5 minutes. After those 5 minutes, the report comes and host status is updated. If the out of sync interval is set to 30 minutes and the report would come in 35 minutes, it would be considered out of sync. Therefore we have two intervals - 1) is the expected frequency of the regular run (reported_origin_interval) 2) the max lenght of configuration run to accept (default_report_interval).
I think when this was introduced for all cfgmgmt subsystems, the intention was to allow every subsystem to define it’s own single interval, so you’d only use reported_origin_interval, e.g. setting “Puppet interval” to 35. However there was a concern raised about backwards compatibility, so we ended up still adding default_report_interval so people could still be setting Puppet interval to 30 and Out of sync to 5. The problem is that default values remained as 35 and 30 so it does not make much sense.
If you’re touch this I think we could finally start using “#{origin}_interval” only to make this simpler. We also still fallback to the Out of sync interval in case plugin don’t define its own interval, perhaps we could update all remaining plugins if needed (salt, chef). Last note, the default_report_interval also takes host parameter into the consideration, that functionality should probably remain, but could move to the “#{origin}_interval” method.
Thank you, Marek, for this very good explanation. I think that it would be nice to clean things up and clean up a little bit. I can work on this. Let me sum up what needs to be done:
In a first step:
Overwrite global “outofsync_interval” with plugin specific “#{origin}_interval” if available (I would leave the fallback for now, it can still be removed later)
Move the host parameter override from global setting “outofsync_interval” to plugin specific “ansible_interval”
Rename “puppet_interval”, “ansible_interval” settings to something more meaningful like “puppet_outofsync_interval”, “ansible_outofsync_interval” (–> needs an update of the Ansible plugin)
Update scope for dashboard such that it takes into account host specific outofsync settings
Dashboard might need some update as well as it shows only the globally set “outofsync_interval”, “ansible_interval” and “puppet_interval”
In a second step:
Add “plugin_outofsync_interval” setting to remaining plugins (Salt, Chef)
Remove global “outofsync_interval”?
Is there anything else I have forgot? What do you think about renaming the settings (step 3)?
I believe that’s the way to go I definitelly agree with switching to override even if it might break backward compatibility and make the interval shorter for some users and cofuse them.
If we also rename in the same release, it would be great as users would more easily notice we’ve touched this funcionality.
I’d just add a step to note this in release notes and preferably also demo it
We are looking into reimplementing reports from scratch and one think striked me in this regard - how much useful is the overall Configuration status? I mean, wouldn’t be more reasonable to implement plugin-relevant statuses only? Host report would typically look like:
Ansible status: N/A
Puppet status: OK
Chef status: N/A
That would mean ditching the generic intervals alltogether as it can be calculated from all specific results (OK in this case).
In my opinion Configuration status does match better to the other ones like Configuration status and in most environments only one solution is used so no interference here. I only know some where Puppet and Ansible is used in combination and perhaps more were responsibility for Puppet or Ansible is shared between departments where also a finer state would not help.
But when I look at the many states added by Katello, perhaps it would make sense to have one more level than global and sub-status in the future? Could also help UI/UX with a nicer presentation.
Correct me if I am wrong, but logically, aren’t there two kinds of statuses?
Normal status which is bound to a feture (Ansible out of sync, Puppet out of sync, Build…)
Composite status which is just a set of other statuses and can have a common implementation for everything (Configuration overall, Provisioning overall status etc)
I believe we do not need any special implementation for Configuration management, it is just a list of statuses which must be OK in order for such an overall status to pass.
Yes, correct, but from my impression we have at the moment both kinds on the same level.
To stay with the Configuration status as example there is only the composite one right now and for an overview it is enough in most environments, but adding the ones for the feature would add a level of details that could be helpfully in some environments if not bloating the interface.
With Katello there are more representing the different features of content management like subscription, errata and traces, but no composite one. And this feels a bit bloated at least for me and some customers I had.
So this is why I think also design of the presentation in the web interface matters here for what makes sense to implement. But it could also be a different task for UI/UX of course.
Ansible only touches the configuration status if roles assigned to hosts were ran. Other ansible based job (like one-time deployment) do not generate the config report. So even in this combination, the clash is unlikely.
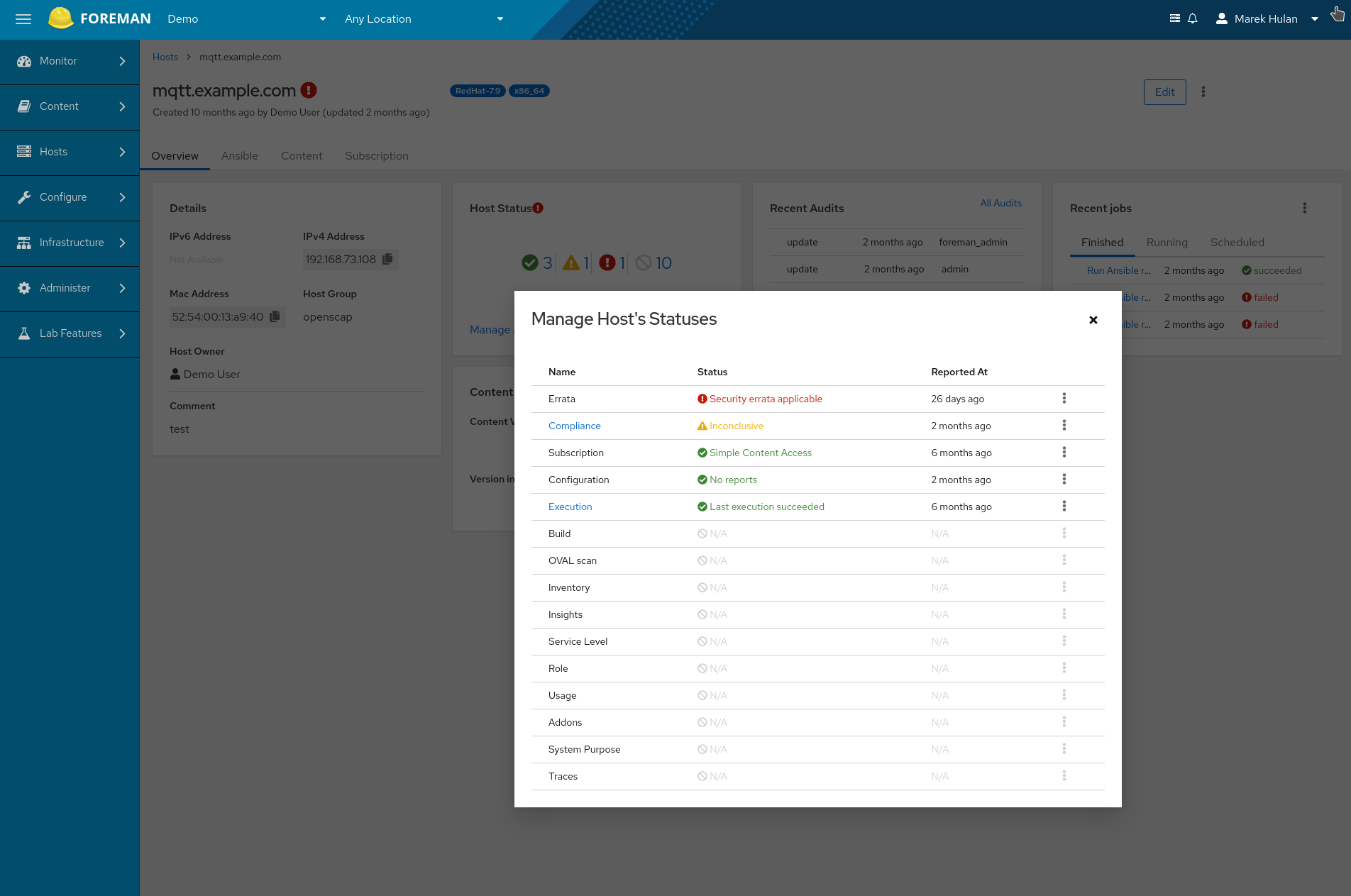
I think that the new host detail page addressed the issue pretty well, let me add the screenshot here. We’ll be happy to hear feedback though.
Perhaps, but I feel that adding additional layers would make it hard to understand. The sub-status represent one functionality or use-case for the host. I think that applies to the Configuration status as well, it’s just a technical detail that configuration can be achieved via multiple providers.
Similarly the REX status should represent the SSH, Ansible and in short future pull provider execution status. The use case is to execute some job, regardless of the transport mechanism. Ideally it should have also represented katello-agent but that was never implemented.
Oh we do have quite many of them. If this is the interface we will be landing with, then shall we simply drop Provisioning status and create some sort of groups like Provisioning, Configuration or Content? That would be simply a new column in status model. Then we could actually just present these groups on the detail page if we want to.
I think we shouldn’t really introduce groups of statuses. We’d quickly end up with a single status in a group (traces, build, OVAL etc). Note that the build mode can contain multiple values that are considered green. So the build status should be the group for all possible build states. I don’t personally see the value until we have at least 3 statuses for each suggested group. Note that only the relevant statuses are displayed next to green, yellow and red icons, the rest is there for user to know, what other information could be obtained but may not ever be interesting. It gives user the information that e.g. we don’t have any Compliance data for this host.
If we want to solve the problem of user seeing to much while they are e.g. interested only in Compliance or Provisioning, we should use either user preferences or permissions for that.
On something slightly different, Puppet run interval is set via runinterval config variable, but when I grep our community templates, I see nothing. Why Foreman does not set this? We apparently have a setting for that, I would expect Foreman to boostrap Puppet correctly.
Or am I missing something in here?
I am tryíng to collect all my thoughts on this regard and I think it would make sense to leverage this configuration value for both boostrap and also status.
We consider configuring Puppet to connect to the correct Puppetserver (and CA) as bootstrapping. All management after that should be done using configuration management. I’ve always used GitHub - theforeman/puppet-puppet: Puppet module for Puppet client and server to manage the Puppet configuration. It has the benefit of also updating all hosts that are already installed.
Foreman’s run interval historically (before the changing due to Ansible) was always a bit higher than what Puppet is configured to. For example, if Puppet runs every 30 minutes but a run could take a minute, then a host may show up as out of sync for a minute every 30 minute. This grace period wasn’t captured. This means Foreman’s run interval was typically set to 35 minutes while Puppet was configured to 30 minutes. You could argue for two settings, but I think very few people actually change the run interval and stick with defaults.
So it is expected that Puppet manages also Puppet client configurations. Therefore it makes no sense to use the interval to setup this in puppet.conf. Okay.

 Thanks in advance!
Thanks in advance! I definitelly agree with switching to override even if it might break backward compatibility and make the interval shorter for some users and cofuse them.
I definitelly agree with switching to override even if it might break backward compatibility and make the interval shorter for some users and cofuse them.