I’m hitting issues with ComputeResource mess all the time, especially problem with consolidating attributes to create / update VMs for Hosts. This is a long lasting issue [1]
I’ve once again came up with weird proposition how to do stuff
If you have refactoring ideas, that you think will take few releases to implement or you’re unsure you will finish them, please read this proposal
Design for this effort
Code for compute resources is a mess. Most likely because it is hard to tackle as hardly anyone has all the compute resources, so testing is hard. So anyone who tries gives up after a while. Like me two years ago
This time with less enthusiasm and bit more experiences I can see it is not a task for one PR. What’s worse it is probably not a task for one release, because it works, so noone will invest continuous uninterupted effort in cleaning up the code.
That’s why I’ve decided to go step by step, as I’ve done in the past with simmilar refactorings. Usually the problem is, that I do the first steps, then get interrupted and never get back to it.
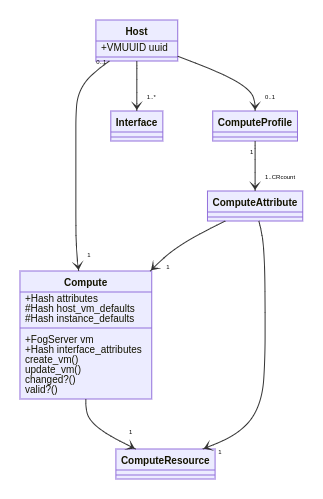
So this time, I’ve come up with an idea to add step of documenting the idea I have, so anyone (even myself after some time) can pick it up much more easily and continue where I left of, so I propose for every step here I’d first come up with a high level diagram for current state and to-be state. The additional benefit would be we get a high level developer documentation for a code most developers are afraid to touch. And even version control changes to this architecture.
In my opinion, Compute Resources the way they are implemented today has one major drawback - Foreman needs direct connection to the hypervisors (or manager API). Foreman does support HTTP Proxies but not all CRs are actually HTTP calls (e.g. libvirt uses its own protocol that can also be tunneled via SSH).
What I think could be a good path forward would be to leave the current codebase as-is and build a new and generic Compute Resource that would talk to a newly created Smart Proxy (Compute Resource) module which would be built from scratch. We would have a well-defined REST HTTP API for all operations decoupled from ruby-fog. This way we could use most of the Foreman core code to build existing compute resource smart proxy plugins but we could also build entirely new plugins without fog.
The new (generic) Compute Resource could live next to the old Compute Resources for couple of releases until we are sure everything works fine. Transition could be really smooth, just define new CR and move hosts to the newly created CR, then delete the old CR.
This way we could start with a clean table, reuse most of the current code in a new fashion and build a clean REST API.
I can’t imagine us realy doing that. I already mentioned this is an area that works so noone wants to touch it. And your sugestion would need major design discussions (eg should we have this in smart proxy? or create separate compute proxy?) should we keep fog, or try to remove it, what about orchestration, should that go to that proxy?
I agree it would be nice to do, but even for that effort I believe we should first make more clear API and flows for compute resources, today we somewhere use directly the fog methods, somewhere our own comes into play, so we would need to clean up before moving away from direct communication anyway.
I’d agree though that it is a nice desired state, but that still can’t be done without some anchor, that would comunicate this intention to future Foreman developers (ourselves and new developers). Because that can’t be done in one release.
This was an proposal how to give us such anchor and achieve such a “huge” shifts that will not even be worked on fulltime and will take few releases to get done. I understand painpoints of having it in developers_docs, and I agree there should be page that would have clear links with the code, but I don’t know how to build that from scrach. Though I strongly believe it (something like my proposal) would help us not to discuss the same changes over and over.
I was trying to encourage you for bigger changes but it looks like you’ve already seen enough evolution is indeed better than revolution in this case. Well, I tried.
If you intend to file PRs in this regard, I think we need to have those changes tested for each one of the compute resources we ship in order to make sure we don’t break stuff. Obviously we cannot test them all, but having a list of minimum CRs we want to make sure all patches are working with is important.
I can do code review and testing on libvirt, unless there is a volunteer, then we should ping all owners of major CRs for final blessing. That would be likely ovirt, vmware, openstack, ec2, gce and azure. We can probably create a table with checkboxes and ping owners from there once review is done.



 evolution is indeed better than revolution in this case. Well, I tried.
evolution is indeed better than revolution in this case. Well, I tried.