I’ve had a big debug session with Claude Opus, and this is what Claude came up with, hope that can help narrow down the issue/help on where to look:
Update: third batch of diagnostics, 13 wedges across 4 nights.
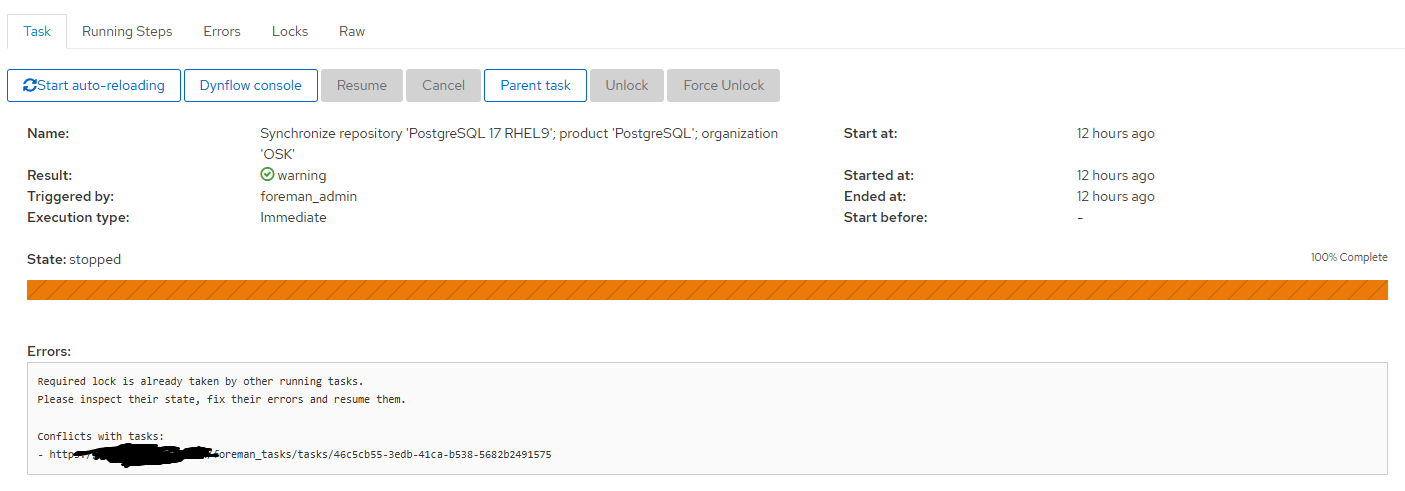
Strongest finding: every single wedge is a rolling clone, never a library instance. All 13 had library_instance_id set. Library/source repos never wedge — only their clones.
When grouped by root_id:
-
root 8 (Debian 12 backports): 3 clones wedged (across 2 different Rolling CVs), within 1 second of each other
-
root 16 (RHEL 9 BaseOS): 2 clones wedged (Test + Prod env of same CV), within 375 ms
-
root 202 (PostgreSQL 15): 2 clones wedged (Dev + Test env of same CV), within 545 ms
-
roots 56, 57, 59, 173, 201, 205: 1 wedged clone each
The sub-second timestamp clusters I mentioned earlier line up exactly with the same-root multi-clone groups. So the wedge correlates with multiple RefreshRollingRepo tasks running concurrently for clones of the same root repository, not with concurrent activity in general.
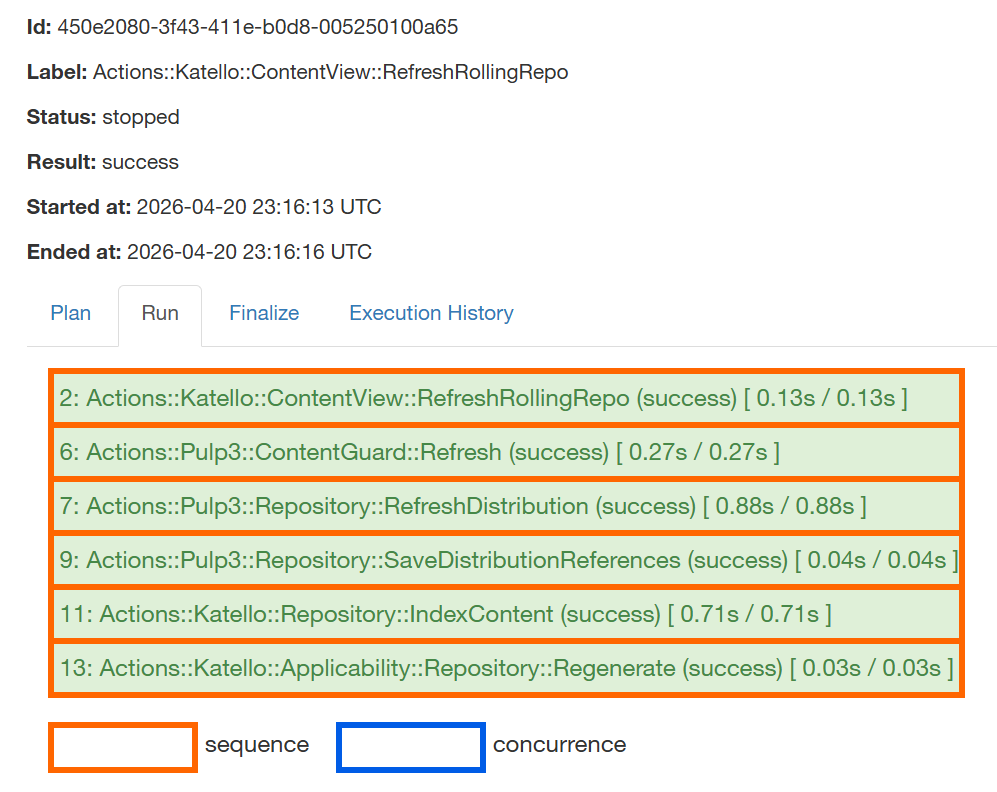
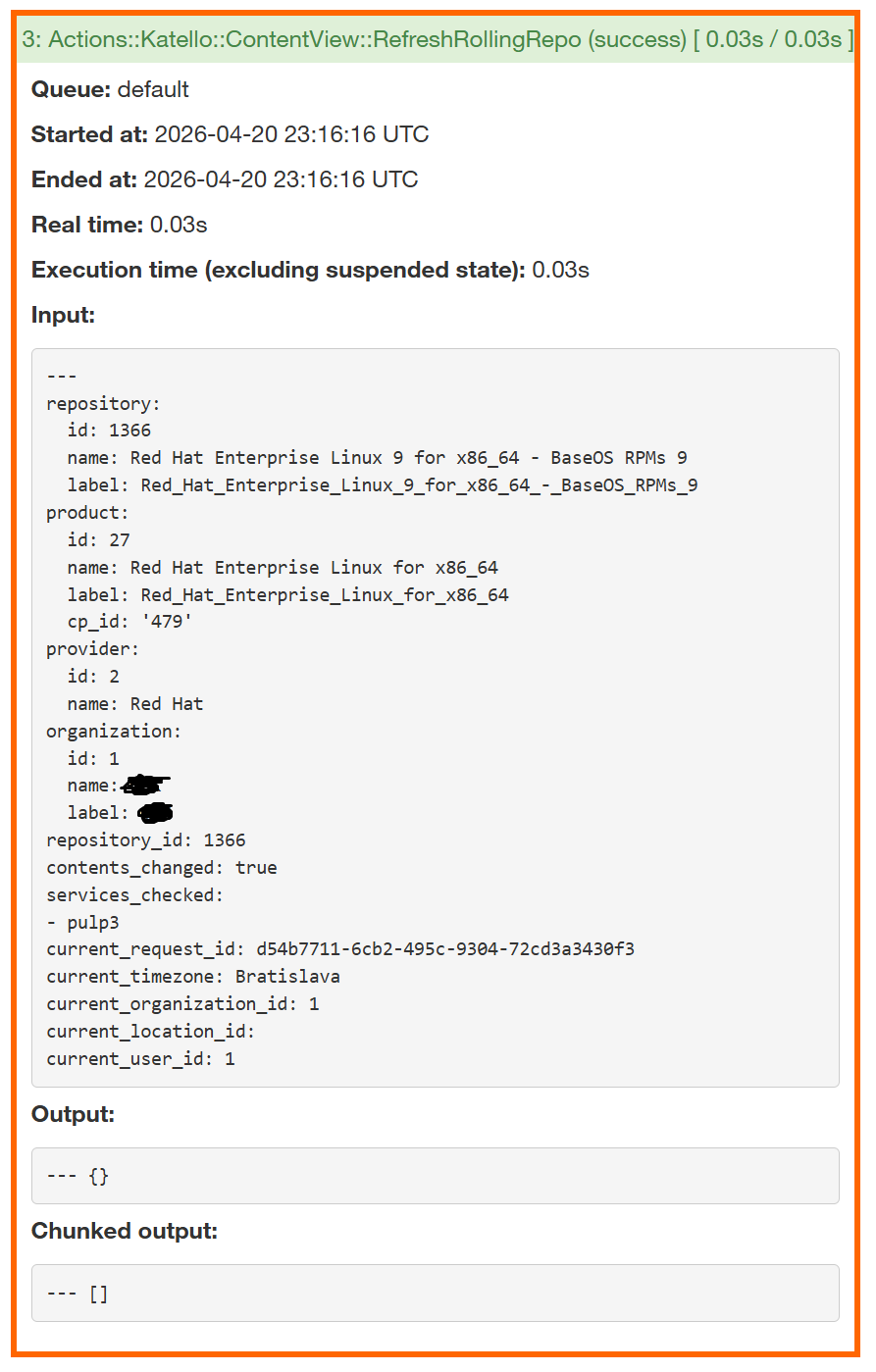
Updated hypothesis: when a library source syncs and has multiple rolling clones across environments / Rolling CVs, RefreshRollingRepo is spawned once per clone in parallel. The clone-update path likely ends with a callback or event keyed on the shared root repo (Pulp publication regen? applicability? content count?). When N siblings try to deliver that event in parallel, only one’s wrapper-state-update completes cleanly; the others’ completion events get lost. Sources never wedge because they aren’t competing with siblings on shared state.
Workaround in place via the cleanup script. Pattern is now reproducible enough that it should be possible to write a reproducer: create a Rolling CV with a single Red Hat or large custom repo, promote it to Library + Dev + Test + Prod, trigger a sync, observe at least one of the four RefreshRollingRepo tasks wedging.
(personal note to this though, this does not happen always on every repo, so it might take couple of attempts)
Update with two more diagnostic findings.
Sibling-clone correlation generalizes. Followed up on the “loner” wedges from this batch (single wedge per root). All 6 loner roots have many rolling clones — 20 each for the Red Hat / Zabbix ones (across 3 CVs), 4 each for the Postgres ones (in 1 CV). So even the loner wedges came from sources whose sync triggered many concurrent RefreshRollingRepo sibling tasks. We just happened to catch only one wedged sibling per root in that batch.
Reframing the hypothesis: the wedge rate scales with the number of rolling-clone siblings of a root, because all of them fire RefreshRollingRepo in parallel when their source syncs. Bigger sibling group = bigger chance one of them loses the post-completion race. This explains why RHEL/EPEL/Zabbix repos wedge more often than small custom ones — those library sources tend to have many more rolling clones promoted across environments.
A second failure mode. Out of 14 wedged task rows from the past 4 nights, 13 hold a stale lock; 1 has the same planned/pending wrapper state and the same plan stopped/success underlying execution plan, but locks=0. The wrapper update failed in both cases, but in this one case the lock was released cleanly. Suggests the post-completion path has at least two sub-steps that aren’t atomic — sometimes both fail, sometimes only the wrapper-update fails. Not blocking (no stale lock) but still creates a stuck task row.
Reproducer hypothesis: create a custom repo, add it to N (e.g. 5–10) Rolling CVs across environments. Trigger a sync of the source repo. Expect at least one of the N spawned RefreshRollingRepo tasks to wedge with the symptoms above. Probability scales with N.