Problem:
Randomly, the sync plan task gets stuck and never finishes. We have had similar behaviour ocassionally in the past, canceling the sync will temporarily fix it (which means, the next sync will usually work). The issue started to occure once we upgraded to Foreman 1.20/ Katello 3.9
Would you explain this a little more please? I am not sure what you mean. In general, all repositorys are syncable through Katello. As I tried to describe, some of them just won’t finish on some days.
Once the problem occures again, we can test if the task resumes after a restart. My coworker cancled the task from yesterday, so I cannot test with the current occurance.
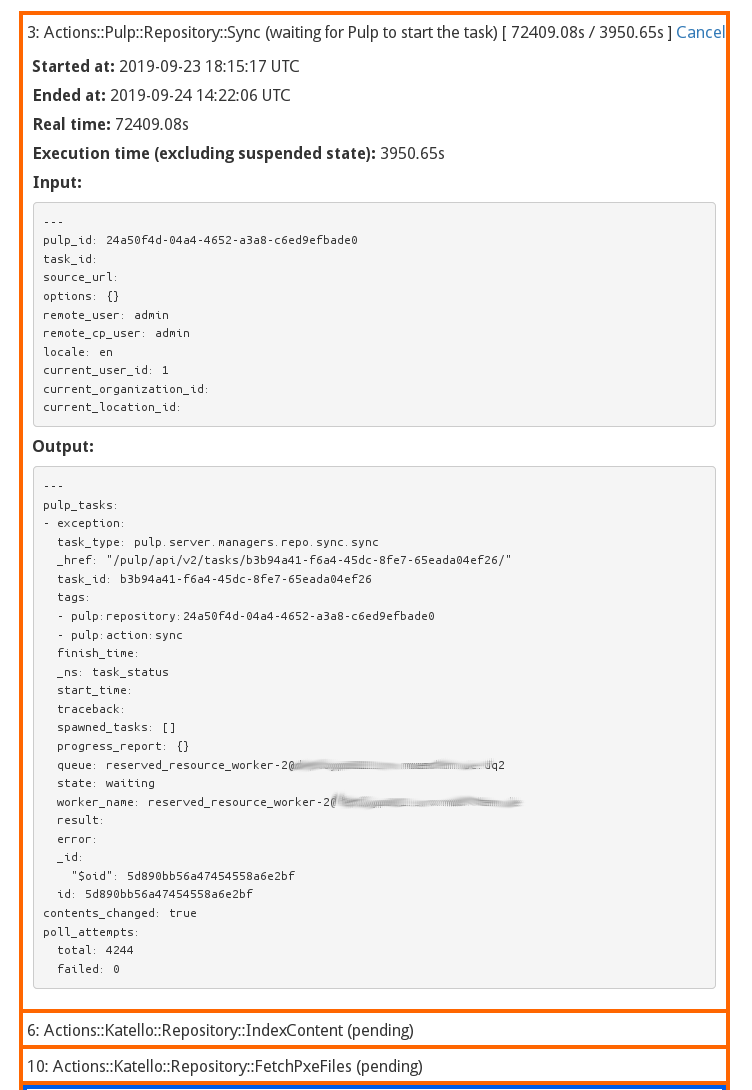
The problem reoccured again tonight. Looks like the same Repos are affected as last time.
The Pulp Log can be found here. The task for the stuck started 20:15:18, I captured the timeframe from 20:10 to 20:40, I cound not spot anything out of the ordninary, though.
Currently, the logs are a loop of the following messages every 5 minutes:
Sep 26 08:43:36 foremanserver pulp: celery.beat:INFO: Scheduler: Sending due task download_deferred_content (pulp.server.controllers.repository.queue_download_deferred)
Sep 26 08:43:36 foremanserver pulp: celery.worker.strategy:INFO: Received task: pulp.server.controllers.repository.queue_download_deferred[224cc063-2390-4b82-a493-c614a73f66df]
Sep 26 08:43:36 foremanserver pulp: celery.worker.strategy:INFO: Received task: pulp.server.controllers.repository.download_deferred[7a5b6991-6fe0-40a4-98d6-651032a95ece]
Sep 26 08:43:36 foremanserver pulp: celery.app.trace:INFO: [224cc063] Task pulp.server.controllers.repository.queue_download_deferred[224cc063-2390-4b82-a493-c614a73f66df] succeeded in 0.017157536s: None
Sep 26 08:43:36 foremanserver pulp: celery.app.trace:INFO: [7a5b6991] Task pulp.server.controllers.repository.download_deferred[7a5b6991-6fe0-40a4-98d6-651032a95ece] succeeded in 0.0195524422452s: None
Sep 26 08:43:36 foremanserver pulp: pulp.server.db.connection:INFO: Attempting to connect to localhost:27017
Sep 26 08:43:36 foremanserver pulp: pulp.server.db.connection:INFO: Attempting to connect to localhost:27017
Sep 26 08:43:37 foremanserver pulp: pulp.server.db.connection:INFO: Attempting to connect to localhost:27017
Sep 26 08:43:37 foremanserver pulp: pulp.server.db.connection:INFO: Attempting to connect to localhost:27017
Sep 26 08:43:37 foremanserver pulp: pulp.server.db.connection:INFO: Write concern for Mongo connection: {}
Sep 26 08:43:37 foremanserver pulp: pulp.server.db.connection:INFO: Write concern for Mongo connection: {}
I will try a restart of the service later and report back about whether the task will resume afterwards.
So, I just restarted the Foremen stack and the task now says it finished. Everything in that subtask is now in state “success” and all the other steps tell me they only took some miliseconds to finish, which matches with the “regular” completed tasks.
Sorry for the late reply, work has been very busy these past few weeks.
Just wanted to let you (and others that might stumble upon this issue in the future) know that the problem seemingly resolved itself after RHN was back up to full performance. Looks like the degraded performance on RHN that took some time after their outage caused some hickups in our environment.
Thanks for your help though!