
Smart Proxy Container Gateway for Katello
The Container Gateway Smart Proxy plugin is being developed to enable container registry functionality on Pulp 3-enabled smart proxies. Currently, on Smart Proxies, the Pulp 3 container registry is not properly exposed and any container image can be pulled without auth. We’re looking for feedback on our initial designs.
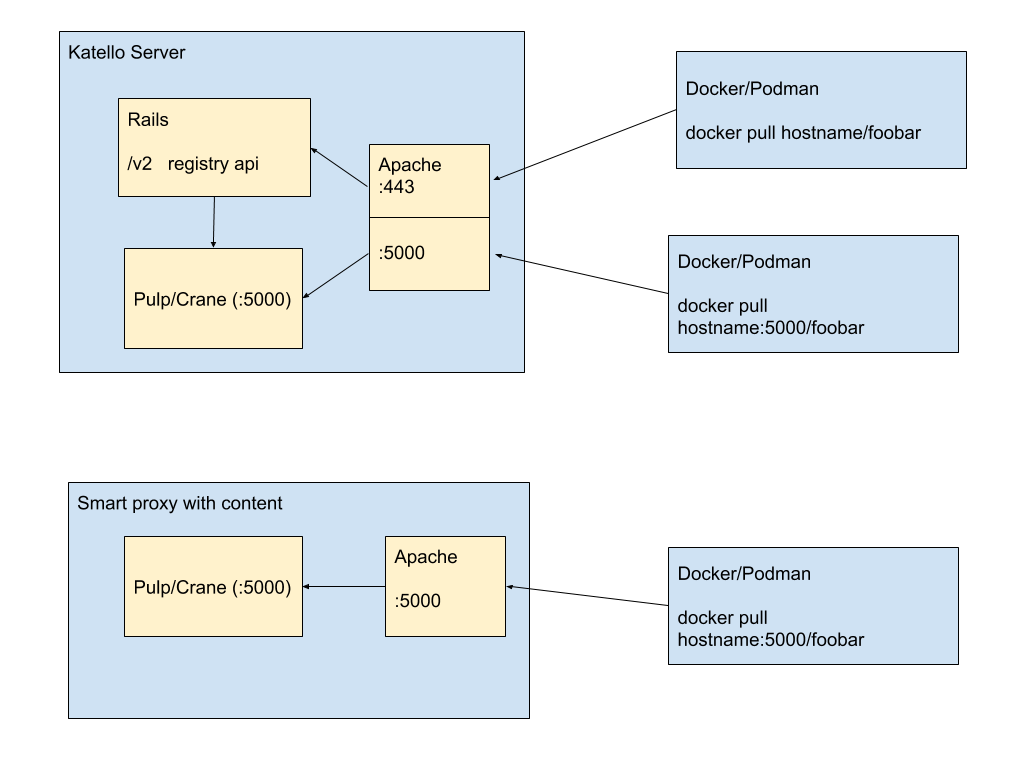
Current Pulp 2 model
Two registries on Katello:
:5000
- Unauthenticated pull
:443
- Support for Authenticated repos, featuring full Foreman authorization
- Support for ‘docker search’
One registry on the Smart Proxy:
- Unauthenticated pull
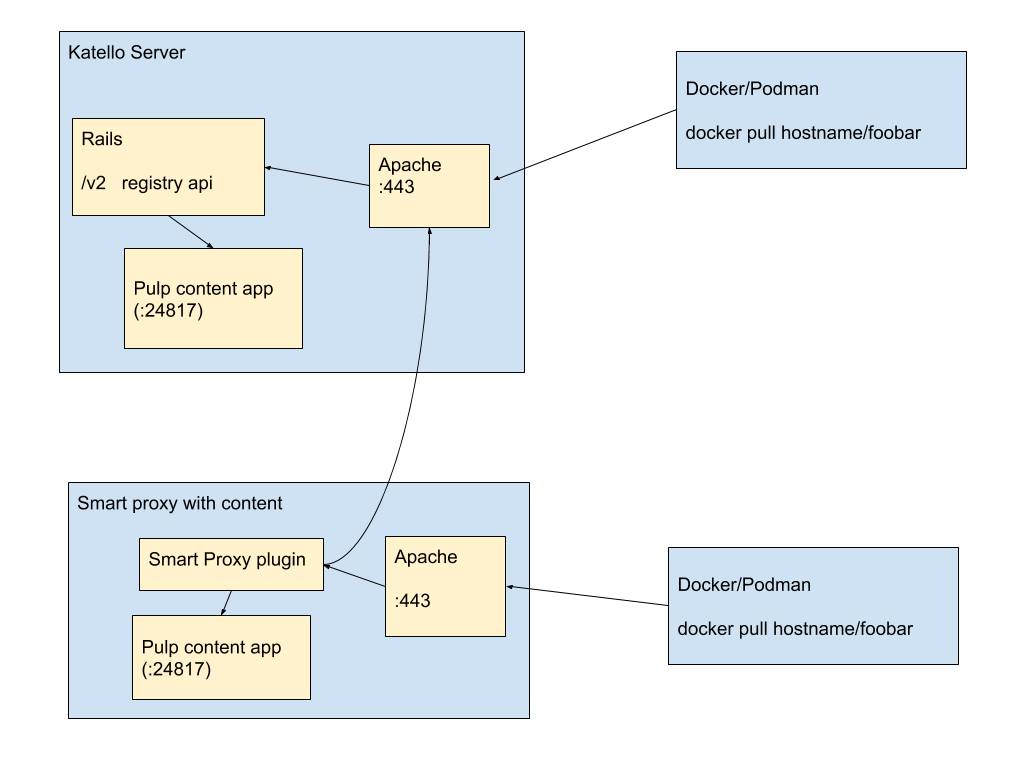
WIP Pulp 3 Model
Single registry with:
- Support for Authenticated repos, featuring full foreman authorization
- Support for ‘docker search’
Longer term, refactoring:
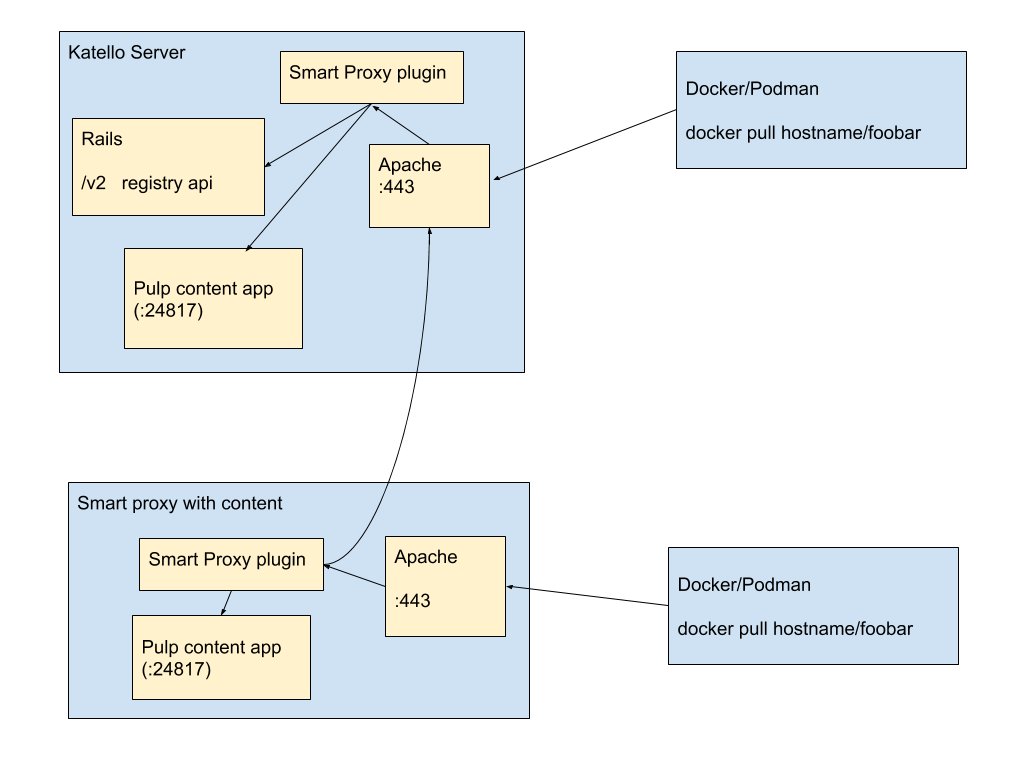
Basic idea: the Container Gateway exposes the Pulp 3 container registry in a usable fashion and caches auth information from Katello.
Implementation Details
Repo: GitHub - Katello/smart_proxy_container_gateway: smart proxy plugin providing an authenticated registry backed by katello, foreman, and pulp
→ Current state: unauthenticated repositories can be browsed and pulled. Next step: handing auth
API Handling
- Manifests and blob GET requests redirect to Pulp 3
- The
_catalogendpoint GETs the container images that a user is allowed to see - The unauthenticated repository list is sent via PUT from Katello at Smart Proxy sync time
podman loginrequests ensure a user token is available (check cache and reach out to Katello if necessary) and presents it to the container client (todo)
Caching
- Cached data exists in a PostgreSQL database
- PostgreSQL availability is guaranteed since Pulp 3 is required
- ORM library: Sequel
- Database migrations are automatic. The database is checked at each instantiation of the DB connection object.
- Unauthenticated repo cache: list of repositories that don’t require auth
- Updated at sync time
- Authentication cache: mapping of tokens checksums to users with expiration time (todo)
- Updated at login time
- Authorization cache: mapping of users to accessible repositories (todo)
- Updated at login and sync time
New Apache configuration
- Check the README in the GitHub repo
TODOs after initial release: packaging and installer support.
Thanks for reading, let us know if you have any questions or feedback.