Remote Execution has been around for a while now and has served SSH-based and Ansible execution very well. In many environments these are not options due to either security or networking concerns.
Katello-agent has provided an alternative for a long time that worked in an environment where SSH was not available or the Foreman/Katello server or smart proxies did not have the ability to connect to a client. However katello-agent only supported a small set of actions around updating packages. There has been a long desire to create a ‘pull’ based provider that has the features of REX but with a deployment model similar to katello-agent. A few of us have been discussing this for a while and even though its pretty early in design, we felt it was ready for public feedback. This will not replace REX over SSH, but will be another provider option for REX.
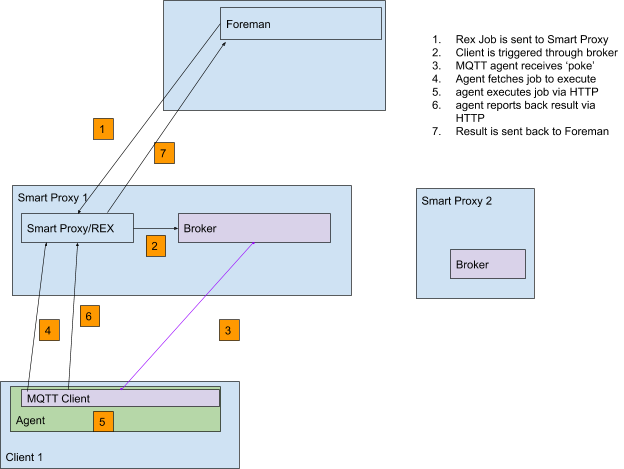
The solution uses MQTT as its messaging protocol and includes an MQTT client running on each Host. Here’s a Flow:
A broker has not been selected yet
If a client picks up their message and fails to fetch the job or return the results within some amount of time, a timeout will ensue and the job will be marked as failed
Fetching the job and Submitting the results via HTTP allows us to scale via the HTTP layer and use similar mechanisms to the existing REX ssh provider.
As part of the discussion, we wanted to vet a pure messaging approach, that does not use HTTP for fetching the task for submitting results:
I used MQTT before and was very happy on its quality and system resources (very light), i however nerver attempted in a really large scale (e.g. 1000s of clients) or in a multi mqtt servers topology, is that in scope for your design? or rather start small and see how it scales?
regardless, +1
I do wonder if we need to thread the MQTT topic structure as an API… as it could allow various clients interacting with it in various ways.
I may be missing something, but it looks like both images are the same?
Also, it looks like the two options being considered are using a combination of MQTT and HTTP for communication (or is the second one supposed to be purely MQTT?).
I am curious if the option of using only HTTP with a polling agent considered and if so why was it dropped?
That would reduce the complexity of adding another piece of infra (broker) to manage, reduce the requirement of maintaining an open communication channel between the client and broker (with the associated firewall rules and potential networking issues).
The down side would be that the trigger wouldn’t be immediate, as it would take up to a polling interval for the client to call the proxy asking for jobs, but the interval could potentially be adjusted (by the agent itself!) for scale considerations or to allow several tasks to be combined into one run. I expect if a host has no jobs to run returning a quick “nothing to do” response should be possible in the 10-50ms range, allowing a single proxy to potentially service thousands of requests per minute.
I have also similar concerns as others. Having some background in messaging but only briefly scanning over some MQTT/ActiveMQ materials, I do believe that this protocol is meant to be lightweight on clients (it’s targetting for IoT), this is a bit irrelevant. Our project aims to manage servers, these are not ESP chips running on batteries and they are capable of handling more complex connections just fine.
What’s more important is the broker implementation. I believe the plan is to leverage ActiveMQ Artemis which is already used in Candlepin has a ton of features and MQTT is just one available connector. The protocol itself is based on TCP/IP, to scale that I expect some OS-level things to be customized (opened files, available ephemeral port range etc). Also, this might require another instance of the broker fine tuned for this use case - for Candlepin the priority is robustness and durability while for ReX it might be performance, low-latency or low-resource consumption perhaps.
We should definitely perform some performance tests over MQTT on Artemis configured for Candlepin or configured with default values or fine-tuned to see some results before we commit to this. The goal is to verify the broker, not the protocol (which does not matter too much). I am a bit worried about memory consumption to be honest if we end up running two instances on a single host.
Another thing to keep in mind is that if we used let’s say WebSockets or even dumb HTTP polling, it passes via firewalls and HTTP proxies can be easily deployed by users and customers. It’s something everybody knows how to setup, usually it works out of box. I would not rule out HTTP polling too because it can be easily scaled by tuning the delay between polls and it can be even dynamically controlled by a response HTTP header (next poll in X seconds). With MQTT all TCP connections are opened forever.
What I am trying to say here:
When considering another ReX provider, we should focus on a broker rather than a protocol.
We should test how a broker scales up before we commit.
I’d consider HTTP(s) WebSockets with simple polling fallback as an alternative.
That is exactly the concern with a pure polling based model. How does a user balance that polling interval without overloading the server but putting themselves in a place to be able to push out critical updates ASAP. How do you prevent all systems from checking in at the same time and over loading your server?The messaging aspect also allows the server to at least know that the client received the message and then act accordingly from there if no data is received.
I’m hoping we will get some feedback around this from Puppet users for whom the polling model is the model.
One nuance of the HTTP + MQTT proposal is that it can enable this workflow. You could think of the MQTT part as an upgraded workflow. The user could opt to have their clients poll for new jobs, or bake it into puppet for example. Or they can opt to install the broker pieces and MQTT client bits to allow immediate execution of jobs by delivering messages to the client to let it know it has a job available.
The MQTT + HTTP option does put the burden on HTTP and the scaling of the Smart Proxy.
That is true of the MQTT protocol origins. And to that point, I would ask why shouldn’t look at devices as a place to expand our foot print of manageable hosts. They can be of different sizes and scales. They run and OS and need it managed. They need content, security updates, remote actions, provisioning. They have their nuances as a workload, and choosing MQTT as a protocol provides us looking towards the future of the particular properties of those style deployments that also work for traditional server workloads.
The folks who have been playing around with proof of concepts have primarily used Mosquitto to date due to how light weight it is. Extracting Artemis from Candlepin and using it is an option being explored as well. As @Marek_Hulan likes to point out, it comes with a large starting footprint. Artemis does use the familiar to us Qpid Dispatch for setting up routing across machines.
Sure, I am not saying MQTT is a bad choice. I was trying to point out that MQTT being a lightwight protocol does not mean that brokers are also lightwight and won’t consume much OS resrouces.
That sounds lighter than ActiveMQ, it even supports bridging which is required for isolated networks which is a must-have feature to handle larger deployments.
One important thing to realize is that we need to design topic names from the day one to be isolated. Typically in messaging environments, topic name consist some routing information. For example, from what I briefly learned about MQTT, we could define topics after smart proxy hostname:
proxy1.example.com/topic.name
In this design, individual brokers running on smart-proxies can only bridge the relevant topics which will lead to better performance and scalability.
However I till wonder if it makes sense to explore WebSockets solution. I am assuming writing a dedicated web server for this job (e.g. in golang), we can’t scale out smart-proxy processes running on Webrick easily. Note WebSockets is completely different from HTTP polling, that I mentioned only as a fallback and then I realized it would not work well with ReX which is heavily built around push design.
If we wanted to use websockets, I’d investigate the cockpit being the agent. We already have that connection in REX today, but it’s triggered on demand. If cockpit was able to initiate that, we’d have the persistent connection without deploying any additional services.
However MQTT comes with several other nice things (last_will, QoS, retain messages) that we could use to also address REX for currently offline machines. That would be much harder with pure websockets, we’d need to build the queue ourselves. Mosquitto is really nice lightweight broker so I wouldn’t mind deploying it with every proxy. However we were discussing two options - either broker per proxy or one on Foreman side and do the bridging/dispatching to proxies. I hope @Justin_Sherrill will update the second image soon so you can see that.
Also @aruzicka would you mind sharing some data from your PoC? I know we could optimize the whole thing much more, but to give a rough overview for the scenario you tried would be good.
I would expect that this architecture would scale much better than a centralized solution if implemented properly. Don’t get me wrong, I am trying to challenge us before we decide it’s not like I am against MQTT or something else. Messaging is a great platform to build on and when we decide to go that way, In fact, I’d like to see full commitment taking advantage of more aspects than just transport. Things like durability, priorization, heartbeat, routing and security (these terms will likely have own terms in MQTT) are quite useful. What’s also interesting to explore is MQTT over WebSockets for UI.
From other lessons I’ve learned on provisioning in isolated networks, I’d lean towards federated architecture. Central broker only talking to smart-proxy brokers with the most reliable settings available (message confirming, durability, heartbeat) with end-clients configured for more light-weight connections.
Before we start building anything, I’d check if the broker builds and runs fine on EL7 and Debian9/10 tho
Back when I was hooking up Katello to Candlepin’s internal Artemis to consume events, I started out with some simple testing to wrap my head around Artemis by standing up an an instance external to Candlepin. By the end of that, I had spent quite a bit of time in the documentation. I also ended up looking through the Artemis code to debug an issue I was running into. The experience was good, and things worked the way I expected them to. Candlepin already supports connecting to external Artemis, and I’ve had it running in that mode. I’ve received useful help from the devs too. TLDR: I like the standalone Artemis route.
Re: HTTP Polling, if it’s not necessary, I would prefer to avoid it. My definition of necessary would be anything that is required for us to support large deployments with 60k, 100k, 150k clients using this new tech.
I have no experience with MQTT, but my intuition says that we should avoid clients connecting to the Smart Proxy directly. It’s currently not designed for large amounts of connections, especially if they’re long lived. Also, the connection authentication is not set up at all for it.
The first round of testing of my POC didn’t go too well. I had a single machine (2vCPUs, 8GB ram) running foreman, smart-proxy, mosquitto (the broker) and 100 mqtt clients written in ruby. Kicking off a job against all of them would be fine until the clients started reporting that they finished to the smart proxy. Since all of the clients received the job at almost the same time and all the scripts were the same, all the hosts finished almost the same time, they started hammering the smart proxy at almost the same time. Some of the callbacks would time out, because smart proxy wouldn’t be able to respond to so many requests at once. In here I also encountered a strange bug in curl, where the command would not exit, even if the underlying connection went away. To show some numbers, across several attempts, 80 hosts usually finished successfully, the rest timed out.
After putting some workarounds in place to deal with curl hanging, I was able to get 100 out of 100.
After OOM-killing my entire machine by trying to deploy more clients I reevaluated my deployment strategy. Instead of having N clients, each listening on a single topic I went with 1 client listening on N topics. Since I was mostly focused on testing “our” part of the stack, I didn’t mind slightly diverging from the real world deployment.
With this new deployment I tried running jobs against 1k, 2k and 5k hosts and haven’t encountered any real issues. A single echo hello; sleep 10; echo bye job against 5k hosts run for 29 minutes, which is not too shabby for an unoptimized POC.
Mosquitto (the one I used in my POC) is packaged for both EL7 and Debian buster so we should be safe on that front. Afaik artemis isn’t really packaged for anything, but hopefully it is true to the write once, run anywhere spirit of java.
Same. We would have to start keeping state on the local or remote (or both) side to prevent jobs from being run twice and so on, which mqtt would do for us.
I don’t understand. One of the main goal of a message bus is to enqueue messages so they can be picked up in a reliable way. Are you saying this did not work?
Don’t understand. The communication should be point-to-point, Foreman wants to contact hosts X, Y and Z to perform some action. And reply goes back as well to a specific endpoint. What exactly was or was not working well?
I implemented the first option Justin suggested (mqtt signalization + job retrieval over http). So for every single host and job there are at least two http requests going to the proxy. One to retrieve the job, the other to report results. The hammering was coming from the job results being sent back to the proxy. Delivery of the signal messages to clients over mqtt worked perfectly.
mqtt is not messaging, it is a publish-subscribe kind of thing. Many producers can write to a topic and many consumers can consume messages from a topic. That means we have to “emulate” the required point-to-point nature by having per-host topics. I didn’t have the resources to have N clients, where each client would consume messages from its own personal topic, I had a single client which consumed messages from all the per-host topics.
Mosquitto has an option to establish ACLs based on, among other things, client id from client certs. The idea would be that smart proxy can publish to any topic, but hosts can read only their own topics. My bet would be artemis can do something similar, although I haven’t checked yet.
The reason I was asking about the http polling option is that I’m worried we’re effectively replacing qpid, which is often a black box that is complex to properly set up, manage, ensure stays connected to all clients and debug, with some other tool that would potentially also be complex to properly set up, manage, ensure stays connected to all clients and debug.
There is also a good question about the expected scale and level of service expected - the right solution if we’re aiming for 5K hosts connected to a proxy executing within half an hour of the job triggering is quite different to the solution needed if we’re aiming at scaling to 100K hosts connected to a proxy with <1m to execute. How often are the jobs executed? every hour or maybe once in a few days? Also there is a question of the number of hosts targeted by a specific execution to ask - will most jobs target all machines connected to the proxy at the same time, or will most jobs be targeting a specific host or small set of hosts?