I have a new install of Katello with newest version (3.10).
I’ve done a bit of testing and a lot of reading, but I want to understand more about how others have set it up. I have many repos to mirror, both public and internal, each with different CentOS version (6,7). These are managed by normal “createrepo” and yum.repos.d right now.
First, products:
Should a product be something like “Centos”, or “Centos 7”, or “Centos 7 x86_64”? It seems like “Centos 6” and “Centos 7” are different products. If at some point I’m requested to mirror the 32bit repos for one of those, is that a different product, “Centos 6 i386”?
Repos inside a product:
If the repo is “Centos 7 x86_64”, then it’s clear to add the os/updates/extras to it, but if it’s the more generic such as “Centos 7” or “Centos”, should I add multiple arch and versions (6,7) into a product?
Content Views:
The idea of creating a “locked version” of a product and promoting it is clear. However, what would be an example of a name for a content view? Same as product, should it be “Centos”, or “Centos 7”, or “Centos 7 x86_64”.
I’ve seen some people make a content view called “Centos”, did they put both Centos 6 and 7 repos inside one content view?
If that’s not correct, then I’m assuming I’ll basically have a 1:1 mapping of content views to products. I’m not sure what hosts will overlap for different repos (db hosts, vmware hosts, etc all have different repos on them). Then we have multiple internal repos for our app, I guess each of these should be it’s own content view?
Yum.repos.d:
Right now we are using repos the traditional way, using yum.repos.d files. Is this even possible for us anymore? I manage all those files using puppet to add the correct repos to the correct hosts, and I can have a single file for all hosts using the variables $releasever and $basearch, for example:
– baseurl=http://yum.example.com/repos/puppet5/centos/$releasever/$basearch/
Is it still possible to access the yum repos using that same system, or is Host subscription required?
When I subscribe a host, no files are added to yum.repos.d. I guess the only way to see which repos a host has is to check foreman?
Content Hosts:
In an attempt to understand the subscription model, I subscribed a host as a “content host”. There was a lot of manual clicking for assigning a host to an environment and which content view the host should use, etc, which wouldn’t be ideal for setting up thousands of hosts. I’d need to figure out a way to totally automate this process of subscribing hosts to the correct repos based on their host type and environment during the imaging process. Is this possible?
Also, it looks like I can only assign a single Content View (epel for example), to a host. I can’t figure out how to assign many content views for all my repos to a host. Maybe I’m supposed to use Composite Content View, but this would become very complex and is much less flexible than adding multiple Content Views to hosts depending on their needs. Otherwise, I would have many different composite content views for every variation of repos.
Provisioning using kickstart:
Normally when I image a host using PXE/kickstart, I point to a local centos repo URL in the .ks file. Is this still possible or am I required to use the Foreman provisioning system if I’m using Katello repos?
I think that’s enough questions for now, if anyone has worked through this in a complex environment please let me know what you did. Thanks!
I’m struggling with many of these concepts as well. I can share what I’ve done so far, but as I’m not a seasoned user, I’m not sure if what I’m doing is ideal or not. I’m just jumping into these conversations because I’m hoping that I’ll learn something along the way and hopeful help out someone that’s at a similar point in their learning.
Given that Foreman has the concept of architectures, I’ve decided to create a “CentOS 7” product and to include both x86_64 and i386 repos in that product. Likewise, I have created products for “EPEL 7” and “Puppet 5”.
Yes, I’ve included, os, updates, extras, etc in my CentOS 7 product. As mentioned above, I also have repos for both i386 and x86_64. Of course, because I’m calling my product CentOS 7, I don’t have CentOS 6 repos in there.
I’ll use an example to explain how I think Content Views are supposed to work. In my particular case I’m trying to put together a standard build that I’ll use on all machines in a given Org. On my servers I don’t just want the CentOS distro packages, I also want to be able to use things like Lynis, PHP7.2, the Katello Agent and a bunch of Puppet modules to manage it all. So I create products for Lynis, PHP7, Katello Agent and perhaps Puppet Forge. I then associate repos with each of those products. Then I create a Content View called “Standard CentOS 7” and include each of these products in the view. The view might also use filters to create a stripped down list of packages from the repos.
I should then be able to use my “Standard CentOS 7” content view for building and managing the servers in my environment. I say, “should”, because I’m still beating my head against the wall too.
I’m not this far along yet, but my current understanding is that it’s the Katello Agent that manages package installation based on subscription to a Content View. I’d really appreciate it if someone could confirm that for me.
Again, you’re further along than I am, but I think the idea is that hosts are subscribed to content based upon membership in a host group, a location or an org? So, you set up the host group once and then either assign the host to the host group manually, or use discovery rules to automatically associate new hosts with a given host group. Again, if someone would confirm my understanding, that would be helpful.
See my comment above about how I think Content Views are supposed to work. I think Composite Content Views would accomplish the same thing, but as you’re suggesting, it’s yet another layer of abstraction that you might not need in your environment.
I’m curious about this too, but from a slightly different perspective, because today I was looking at Hosts > Provisioning Setup > Installation Media, in Foreman and wondering why I would be using a public repo to build a host when I have just put all the work into mirroring repos in Katello? Are Installation Mediums showing up in the Foreman interface because of overlapping functionality between Foreman and Katello?
first off, a lot of these questions and the related topics themself are what (to my experience) are the things that trubble nearly every new user the most. After several years of using Katello, I would do a lot of things differently myself if I was starting from scratch now. The genral problem is that everything content related is really complex and there is no “best way to do it”. The correct answer to most of your question would be “it depends”, since it will be a little different depending on what you want to achieve. There are some general guidelines though what I would consider at least “good practice”, but keep in mind that everything I write here is little tainted since I’m mainly looking at these things through the goggles of my company setup.
The Redhat way of doing this is seperating this on a license/subscription basis, so if you need a specialized subscription for it, it will be it’s own product. This works somewhat well for RedHat stuff, but since you technically do not need any licenses for anything else with Katello, this is only transferable to some extent for custom products.
My general advise is: Look at these like they are called, products. If you think something is a different product, create a new one. If it is part of some product you already have, put it there. So I would put everything CentOS in a product called “CentOS” and e.g. everything Foreman/Katello related in a different product (called either “Foreman” or “Katello”) and EPEL into a product called EPEL.
What you always have to keep in mind designing products: If you want to use sync plans (so, scheduled automatic repo syncs), these can only be assigned to products, not individual repos. So if you want to sync some repos using different schedules, these can never go into the same product.
Basically, I would recommend putting these in the same product if you do not have strong reasons to do otherwise.
Here is where the “it depends” part really starts. Generally speaking, the idea of one CV per product is a good guideline. What you should never do is seperate things into different CVs when updating one will probably breake the other if that’s not updated too. If you have the need to update different major releases in different schedules, promote those to different Lifecycleenvironments, or something like that, it might be a good idea to seperate those. If you want all versions updated simultaniously, I would just go with putting all versions in one CV.
They probably did.
Some of this is already answered in my previous answers. Depending on your app architecture, like with products I would recommend creating one CV per app and not per app-component or repo. Building on that, I would go on and bundle as many of those CVs as possible (and reasonable) into one composit content view and let activation keys handle the rest. The only scenario I could think of where you want to split into different CCVs without a technical need to do so is when you have to make sure certain hosts are unable to see certain repos no matter what.
We currently have one CCV set up per operatingsystem (RHEL7, OL7, SLES12) and additional CCVs for things that need to be updated seperately (like our openshift infrastructure and SAP systems) but they all use the same base CVs where possible. This is a setup I am quite happy with and reduces CV maintenence quite a bit.
Basically, this is still possible. Katello repo URLs are somewhat more complicated than this and you will lose some of the benefits of using Katello this way if you do not invest some time in crafting a decent erb template for that. If you want to do http, you have to explicitly enable publishing via http for each repo you create. For https, authentication via clientcert is required and to my knowledge, this requires client registration.
There is one file where subscription-manager places all repos known to it. It is /etc/yum.repos.d/redhat.repo (at least on EL based distros). You can still alway use something like “yum repolist” or “subscription-manager repos --list”.
This is what activation keys are for. I would suggest setting up one activation per Lifecycle Environment + (composit) contentview combination you want to use that enables all the needed subsctiptions and repos for all hosts of that contentview. Then I would set up additional keys for each additional set of products/repos you want to always enable at once. These should not have CV or LCE set since using more than one activation key with these settings will most likely result in a lot of trubble. These activation keys can then be assigned to hosts via hostgroups. The automatic assigning of activation keys can be done differently via parameters in other places as well, but using hostgroups is usually the most convenient way.
For newly provisiond hosts, this can then be setup easily through provisioning templates (take a look at the community templates for some examples). For importing existing hosts with activation keys you will most likely have to come up with some automation around that yourself, wether it is some sort of SSH bulk command or something completely different. I would recommend not trying to use Puppet for this, since to my experience using subscription-manager through Puppet is only useable with a bulk of exec statements and is basically always more pain than its worth.
A word of warning though, since you asked about the ability to use Puppet for managing repo files: If you go this way with subscription-manager handling the repo setup, I would strongly recommend agains using Puppet for any repository already managed by subscription-manager. That will most likely result in a huge mess since the Puppet yumrepo provider does not understand the concept of more than one repo per file and you will probably end up with a lot of duplicate repo declarations in your yum config.
I partly already answered that beforehand, but summed up shortly: Yes, you can only assign one Content View per host and you are supposed to use composit content views for that usecase. I suggest creating the minimum required amount of CCVs to make this somewhat sane and let activation keys handle the rest of the work.
This is still possible but you will need to write your own kickstart and provisioning template for that (or customize the community or default ones). The Foreman provisioning method does nothing differently on the technical side, it just tries to hide some of the work for for you with builtin features usable by the provisioning and PXE templates.
I hope this can help you in grasping these topics a little more.
A lot of these things come down to a point of personal preference and depend on your situation quite a lot. In specific scenarios it is for sure reasonable to some things differently than I recommended, but this is what I experienced to work quite well and is a good tradeoff between complexity and added benefits for our setup.
Thanks for all the insight. We definitely would like to make Katello more beginner-friendly, both from a usability and documentation perspective.
I would like to hear more about what is confusing when you started, there is a lot of good information in the above posts.
@areyus@mason (or anyone else) Could you make a short list of what your points of pain and confusion were when you started? This would be helpful to us to know how we can improve documentation and usability
Hi @John_Mitsch , I’ll take a stab at this. First, given all that has been said about the flexibility of Foreman/Katello and the many ways it can be configured, I think it would be helpful for you to understand the specific context I’m working in. You can see exactly what my goal is, my requirements and the current process I’m following in an attempt to achieve my goal here.
Early stumbling blocks
Trying to make sense of exactly what services Foreman provides in a fresh installation
When I first looked at the documentation I saw this drawing and thought, “oh good I can see a high level overview of Foreman, get a basic idea of what each of its services do and see what will be installed and made available to my lab environment”. Unfortunately, while smart proxies and Foreman’s provisioning model make sense conceptually, I found that there was no clear path to understanding what my lab environment was actually going to look like and what steps I would need to take to bootstrap the environment. I assumed that authoritative DNS, DHCP and TFTP would be an integral part of an initial install In hindsight I now see why this was a dumb assumption, given that many environments will already have DNS and DHCP in place. I also assumed that I could start with Foreman, get the basic provisioning working and then layer on the complexity of Katello and its associated content management. I was surprised to learn that wasn’t the case, which started me down the path of trying to get everything up and running all at once. I understand that Katello is technically a separate project, but given that installing it after installing Foreman, isn’t really feasible; it doesn’t really make sense for it not to be prominently displayed in the Foreman documentation, especially that architecture drawing.
Getting my head around the integration between Foreman and Katello
It’s still not clear to me exactly what needs to be in place, within Foreman and Katello, in order to be able to successfully provision a new bare metal host using PXE.
Getting my head around Katello concepts and what is a reasonable starting point
Products, repos, content views, composite content views, subscriptions, activation keys, etc… There is a lot of abstraction going on here and an opinionated process about how managed hosts will consume content from Katello, yet I can find no resources that provide a simple overview of how this is supposed to work or what the best practices are. As evidenced by my recent response to another new user that is trying to make sense of Katello’s content management, it’s clear that I still don’t really get some of these concepts.
Trying to produce a repeatable automated install
Given my interest in Foreman, it shouldn’t come as a surprise to anyone that I want my Foreman server to be built in a repeatable fashion. I really don’t like hand built systems, especially when the process is a dark art and I’m trying to protect my company from a scenario where I’m hit by a bus (or maybe something more fun like a mountain biking accident). As I move forward on this project and I see how complex the installation process is, this desire for a repeatable installation process becomes more of a necessity. Even after getting my head around some of the documentation gotchas, chicken and egg problems with bootstrapping a lab environment from scratch and beginning to make conceptual sense of how Katello fits into the mix, I’m still not at the point where I have created an automated process for delivering the base level of functionality that I’ll need for provisioning new hosts. I keep running up against against surprising issues.
For example, I learned that setting a default org and loc in the Katello answer file, doesn’t actually set the default org and loc. If after completing the install, I run hammer defaults list I see nothing. However, if I use Hammer to set the default org and loc, then a bunch of subsequent hammer commands (such as hammer architecture list) will fail with a useless message. I had to work out, through trial and error, that the correct approach is not to set the default org and loc (either in the answer file or via Hammer), but to instead provide the org and loc for commands such as hammer subnet create. This has been a slow and error prone process.
At this time, I currently have an install script that configures a fair bit of Foreman and Katello’s basic features, but much to my frustration I still find that I can’t yet create a host via the GUI, without having to make further config changes. Essentially, I still don’t understand what are the minimum requirements for a Foreman/Katello installation that will allow me to successfully provision a new host.
Summary of my initial impressions
Overall, I get the impression that most people must build their Foreman/Katello servers by hand and they probably just fight with it until it works, after that they just trust that it will stay running and they worry more about the hosts that they will build and manage with Foreman/Katello. In order to get to the point of a fully working system, I assume that most people will have been in the community for some time and will have absorbed some of the tribal knowledge of the community, so they manage to avoid the sharp edges and dead ends during the initial setup process. I’m not comfortable with that approach, which is why I’m happy to see so much recent interest being paid to improving the installation process, the documentation and the overall new user experience.
I’m sure I have missed things that would have helped to paint a more clear picture, but hopefully what I have provided helps.
I will try to reproduce my (and other people’s) confusion to my best memory, but by now I’m already using Foreman for about 4 years since our initial setup, and have since then never installed a new one, so some of those memories might be gone already
This is basically the essence that it all boils down to. There are several layers of abstraction going on, some of them even abstracting other layers of abstraction (like CCV → CV → repo). Most of these are at least in some what interconnected with each other, which causes additional complexity. When you are using RedHat Content, it even gets worse because you have to wrap your head around RedHat Products, their repository structure and, in most deployment scenarios out there, also virt-who (and how to get thos guest-of-licenses to work properly). The ability to abstract everything of the yet again with organizations and locations makes this a complete abstraction overkill when getting started.
The other big topic I usually encountered (and to some extent am still experiencing today when trying to use features I did not use before) is the general “where do I have to configure X for it to work, and what do I need before that”. Simple example: We added a new operating system we wanted to manage through our Katello stack. To do a “basic” task like this, we had to add an operating system entry (which by the way turned out faulty at the end because subscription manager wanted it spelled differently and happily added a second entry), new provisioning templates, installation media, gpg keys, product, repos, content view, CCV and some activation keys. Afterwards there was still the task left of interlinking these where needed and finding out again where you have to do certain things in order and and where to configure all those little details you do not change so often, like the provisioning template that should be used. Having to redo atleast some of those steps for every OS minor release (because they are treated as new operating systems entirely) does help with remembering some of these steps, but actually just adds to it being a “not so good” experience. With me being a somewhat seasoned Foreman user/admin, we managed to get this up and running in a somewhat resonable amount of time, especially since we had other OSes already set up where we could simply copy.
Having to set this up the first time, without a lot of experience how the estimated 100 things you can and maybe even have to configure within Katello interact with each other is still really a mammoth task. I have been thinking about setting up a little lab environment for my self for quite some time now, either hosted directly on my workstation or in a lab far away from our datacenter, where I can just try and break things all I want to. The two things that have been stopping me from doing so by now are
The time I estimate until I have all the aforementioned stuff configured so I could actually start playing around.
The simple fact I would probably have to wrestle with the installer a lot, and to be honest I really do not like that thing. I appreciate the fact that thing can basically do everything for you, but everytime I have to use it for upgrades or such, I simply fire it the options that worked last time and simply hope it just finishes sucessfully.
Let me end with a final comment on another quote from mason’s post:
This is most definetly what is is like. If my instance would fall into pieces over night, I would happily wait for a backup of the whole system being restored from some tapelibrary rather then setting it up again and importing the katello-backup tarball.
I hope this is a somewhat understandable writeup. I just dumped what was coming to my mind onto my keyboards, but I hope this is still somewhat valuable.
Thanks @mason and @areyus for the thoughtful replies, there is a lot of great information in this thread. I see some themes emerging, here are a few that I see (doing my best to summarize)
Setting up Formean/Katello using the installer, where to configure things when you do set it up, and how to reproduce this easily.
Clear documentation on things like installing Katello instead of Foreman if you want Katello, how Katello ties in with Foreman
A broad overview of a typical workflows and best practices in Katello re products,content views, lifecycle environments, content host management
General UX issues
There is a good discussion that many of you already found about making foreman easier to deploy and maintain, I’m happy to see this being brought up.
Some of these things are easier to fix than others, I think the easiest area we could start with is documentation. I can think of a few small changes that would help clear up a lot of this confusion. When I have more time I’ll brainstorm some ideas and come up with either PRs or discussions around larger changes
Thanks again for the feedback, it’s really great to have users willing to work with us on improving usability!
Coming up with these commands is a pain, yes, but it’s a one time issue learning to build the servers and then it’s done.
Abstraction
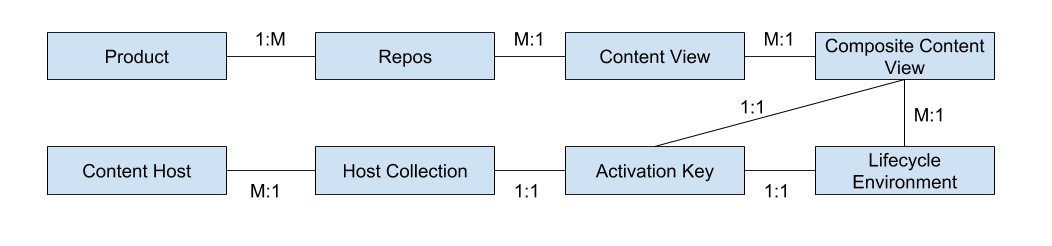
This is the perfect word for the brain-melting thought process a new person goes through understanding Katello. It started out clear in my mind: “I’ll make a product with repos, promote that product to environments, and point to those products using yum.repos.d files”. Once I started understanding more, and mapping it out, I eventually came up with 13 layers of abstraction I had to understand JUST FOR KATELLO, each with either 1:1 or MANY:1 relationships.
Products
Repos
Content Views
Composite Content Views
Lifecycle Environments
Activation Keys
Host Collections
Content Hosts
Subscriptions
Hosts
Host Groups
Locations
Organizations
Had I wanted to do things with Puppet or Provisioning, I’m sure this number would have increased very quickly. As it was, I needed to set up a test environment and map each layer to the others, and create a visio diagram showing where the relationships were 1:1 or many:1. I eventually found that I didn’t need to worry about #9-13 in my list if I’m only using Katello, and so this ended up being my diagram.
After looking at this, and with the help from advice above plus documentation, it became more clear what path I should start to take.
Content Views / Composite Content Views
The idea of content views and composite content views to me just makes a giant mess of the whole thing. I’ve found that a Host Collection can only subscribe to 1 CV or CCV, so it means you have to make CV or CCV like “Centos 7 CCV” with EVERY Product, and now every host using that host collection gets every product, no matter what role those hosts actually. Hardware hosts still get the vmware repo, web hosts still get the mysql repo.
Also, promoting CV and CCV is confusing if they are at different levels. I can version and promote a CCV to different levels than the underlying CVs are at. Now what versions of a repo do my hosts see? I have no idea why a CCV needs promotion, when it should just display the appropriate underlying CV’s to the hosts based on their environment and if the CV was promoted to that env. Or get rid of CCV all together and just let a Host Collection/Activation Key join multiple CV.
The simplest model would be:
Products contain repos, are sync’d and versioned, promoted to lifecycle environments like CV are.
Hosts can get repos in 2 ways:
Host Collections / Activation Keys
– Make a Host Collection that includes several Products and 1 Lifecycle Environment, an Activation Keys lets hosts join it. New Products added to the Host Collection automatically show up on Hosts.
Yum.repos.d Files
– Just point a host to several Products or Repos using yum.repos.d files. A host has no idea about foreman. For example, using a URL in yum.repos.d like:
– http://foreman001.lab.example.com/pulp/repos/QA/Centos7/updates/x86_64/…
– You can see this give the host the “updates” repo inside “Centos 7” product, in the “QA” lifecycle environment.
– Letting people manage yum.repos.d like this creates less barrier to using the product, since nearly all organizations already have complex tools set up to manage these files (chef, puppet, ansible, etc), and foreman is forcing them to abandon those tools. It seems like this is possible already if you know the directory structure Pulp uses but it’s not clear or documented as an “approved style”.
– This would also be useful for imaging tools like Kickstart which expect to point to an OS repo URL
Hey Colin,
I started with Foreman/Katello a couple of months ago and have faced many of the same challenges you describe. For what it’s worth, there are some good Red Hat videos on youtube about Satellite that can add some conceptual definition, if you’re into that kind of media.
One concept that helped me was to visualize content views as vertical lines. RHEL6 is one vertical line, RHEL7 is another vertical line, and my custom repo is a third vertical line, etc. The recommendation seems to be to use one CV for each product (which as you’ve noted, may contain multiple repositories).
Then, I can create custom content views. These are sort of like horizontal slices across those verticals. So I might create a CCV for RHEL6 and my custom repo (but no RHEL7). Or a CCV for RHEL7 and my custom repo (but no RHEL6).
Lifecycle Environments are sort of taking this visualization and adding multiple horizontal slices (the CCV versions). So the version of a CCV that was in dev last month will be promoted to QA this month, and to production next month. Except, all the promotion stuff is manual, so it helps to be clear on the concepts – I’m still a bit shaky myself.
Anyway, probably garbled nonsense, but maybe it’ll spark a bit of light for ya.
This is something I have always thought, and I have brainstormed the idea of showing content views in lifecycle environments as a trello-board-like view, making the promotion lifecycle easier to visualize. I think this is an area we can improve in the UI, where we would like to break down these abstractions, even if it means presenting the same data in a different way and making it easier to perform certain workflows.