
Hello,
I tried to deploy a CentOS 7.5 host via PXE. My Foreman version 1.16.2.
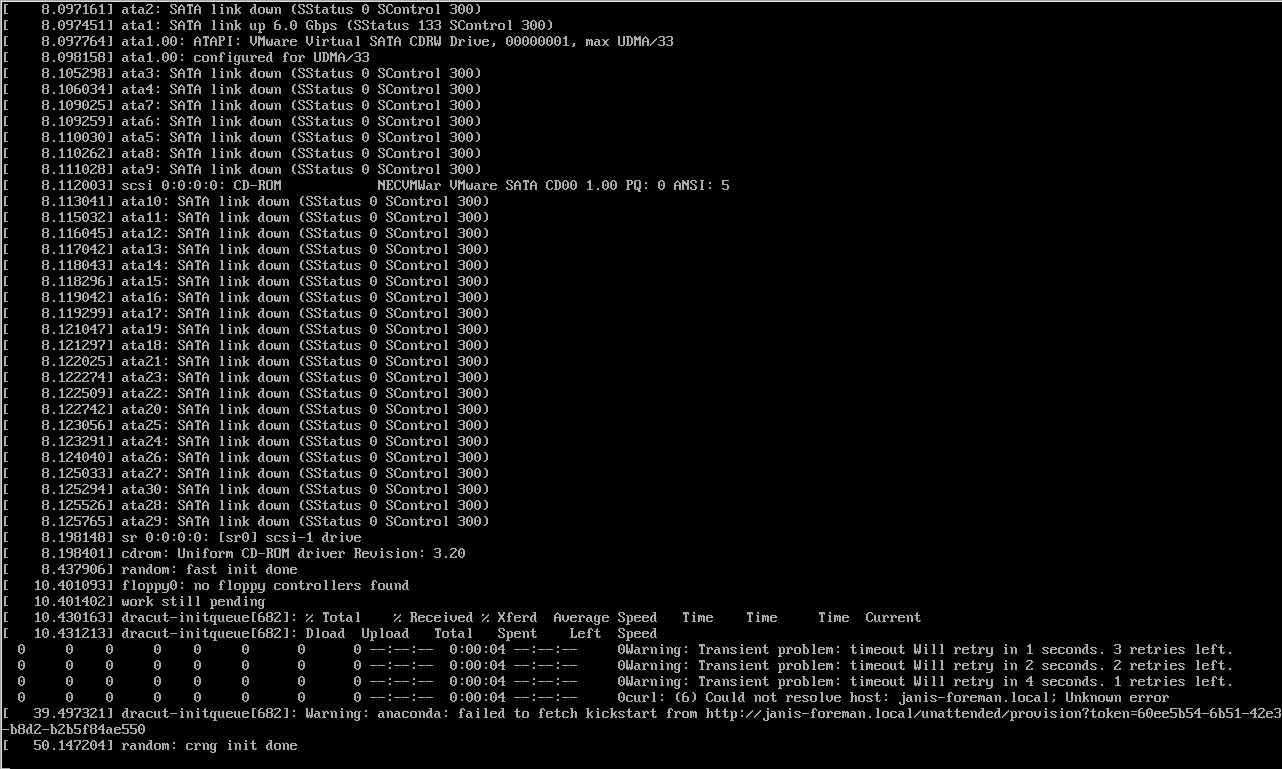
I keep getting the warning: anaconda failed to fetch kickstart from[…] error message. I tried looking in this forum as others had this issues before me but nothing worked.
Hope someone can help me further
Hi,
the host you’re trying to provision can’t resolve the janis-foreman.local hostname to its IP address. Are you sure your DNS is configured properly?
1 Like
Pretty sure I did that and that the host could even ping the server hostname in the dracut emergency shell. Will look into that after the weekend and give feedback of course, thank you for the tip. Couldn`t it be something else?
alright it was a dns/dhcp related issue, nothing related to foremans default configs. thanks for your help! unattended installations are working now!
Glad to hear that, it could in theory be caused by other things, but usually it is the dns 
2 Likes
Hi all, just wanted to include some weirdness that I’ve just experienced which manifested as the exact same problem but wasn’t DNS/DHCP related…
For me the initial discovery image kickstarted just fine however, when it went to kickstart from the default kickstart template I got the SAME ERROR AS IN THIS ORIGINAL POST.
When looking at this (look at the ks= part) via a browser:
[root@foreman-test pxelinux.cfg]# cat 01-00-50-56-0f-03-01
# This file was deployed via 'Kickstart default PXELinux_VidEng' template
DEFAULT menu
MENU TITLE Booting into OS installer (ESC to stop)
TIMEOUT 100
ONTIMEOUT installer
LABEL installer
MENU LABEL Kickstart default PXELinux_VidEng
KERNEL boot/centos7-2-1511-Nf_ahzJutO-vmlinuz
APPEND initrd=boot/centos7-2-1511-Nf_ahzJutO-initrd.img ks=http://foreman-test.velab.cox.net/unattended/provision?token=db0cac76-0a6b-4846-92b8-b4e31808e355 network ksdevice=bootif ks.device=bootif BOOTIF=00-00-50-56-0f-03-01 kssendmac ks.sendmac inst.ks.sendmac ip=10.8.200.179::10.8.200.1:255.255.255.0:::none nameserver=10.7.127.12
IPAPPEND 2
I noticed the status of the below when examing the link directly via web browser:
There was an error rendering the Kickstart default_VidEng template: The specified snippet ‘setHostName’ does not exist, or is not a snippet.
I had been experimenting w/a snipped named “setHostName” and had thought I had commented it out properly in my kickstart template as:
poundsign Set hostname
poundsign <%= snippet ‘setHostName’ %>
Apparantly that wasn’t sufficient to comment it out as the template was still trying to render it…
Once I completely deleted the snippet line life was good again…
I’m not yet a foreman/katello expert so maybe this is a “cornbread newbie” mistake but hopefully this will help y’all… 
-Greg
i get the error only on one machine that was provisioned before. its only this one that causes the error:
tail -f /var/log/foreman/production.log
2024-05-29T10:57:40 [I|app|99a24a09] Started GET "/unattended/provision?token=1493e8d6-d45c-402f-97db-5a80aab4f093" for 192.168.2.104 at 2024-05-29 10:57:40 +0200
2024-05-29T10:57:40 [I|app|99a24a09] Processing by UnattendedController#host_template as TEXT
2024-05-29T10:57:40 [I|app|99a24a09] Parameters: {"token"=>"1493e8d6-d45c-402f-97db-5a80aab4f093", "kind"=>"provision"}
2024-05-29T10:57:40 [E|app|99a24a09] unattended: unable to find a host that matches the request from 192.168.2.104
2024-05-29T10:57:40 [I|app|99a24a09] Rendered text template (Duration: 0.0ms | Allocations: 1)
2024-05-29T10:57:40 [I|app|99a24a09] Completed 404 Not Found in 13ms (Views: 0.5ms | ActiveRecord: 6.1ms | Allocations: 2161)
i do not use smartproxy dns, so i guess this is nsc related?
i flushed nscd and this also doesnt help.
thats really weird because all the other machines get provisioned normally, but the flawed machine doesnt show up in foreman
this is i tried and did not work of course:
- i deleted the hostgroup
- i stoppped foreman proxy
- i deleted the dhcp lease of that server and restarted the server.
- i whiped the dnsc
- i restarted the router
- i checked the puppet facts
so i knew it was neither puppet, foreman, or dhcp, so i cked the tftp logs again:
# journalctl -u tftp -f
Mai 29 13:10:38 cc in.tftpd[6026]: Client ::ffff:192.168.2.104 finished libutil.c32
Mai 29 13:10:38 cc in.tftpd[6027]: Client ::ffff:192.168.2.104 finished pxelinux.cfg/<mac of that machine>
so there was a pxe config file left, so the machine wouldnt boot into default (discovery) which of course makes sense, so i just deleted that file, rebooted the machine and it whent intoo discovery again.
this is really confusing because so man people had the same issue with a totally different cause
I believe it’s reasonable to conclude that this error isn’t primarily due to DNS misconfiguration. If it were, we would expect to see reports citing such issues. However, people are actually reporting problems through these channels:
Misconfigured DNS
Misconfigured PXE Template
An anomaly within Foreman's "Delete Host" process, leading to a residual entry in the TFTP configuration that creates a hard link to a nonexistent activation in the TFTP server's configuration
Regardless, I suggest investigating the failure of your PXE boot process by examining:
Whether PXE templates in Foreman are misconfigured and flawed
A Foreman anomaly (a machine provisioned previously and now attempting to boot from a source other than the discovery boot image served by the PXE template), likely due to leftover PXE configuration, which can be verified through TFTP logs
Misconfigured network settings (e.g., DNS)
The root cause of this issue may not be related to your network settings but rather to the PXE template/configuration you’re using, which determines how and from where you retrieve the source for PXE booting.
I believe another potential reason could be the deletion of the activation key, although this hasn’t been personally tested or reported yet.
Let’s break this down and provide a reasonable solution on how to debug this and identify the root cause:
If you encounter these logs in the production logs, as I mentioned in a previous post, it’s likely that you don’t have a DNS/network-related issue. It shouldn’t be possible for your PXE booting machine to report to the Foreman server or node you’re trying to provision without encountering such errors:
you can also try curl to see if your dns is responding
tail -f /var/log/foreman/production.log
2024-05-29T10:57:40 [I|app|99a24a09] Started GET "/unattended/provision?token=1493e8d6-d45c-402f-97db-5a80aab4f093" for 192.168.2.104 at 2024-05-29 10:57:40 +0200
2024-05-29T10:57:40 [I|app|99a24a09] Processing by UnattendedController#host_template as TEXT
2024-05-29T10:57:40 [I|app|99a24a09] Parameters: {"token"=>"1493e8d6-d45c-402f-97db-5a80aab4f093", "kind"=>"provision"}
2024-05-29T10:57:40 [E|app|99a24a09] unattended: unable to find a host that matches the request from 192.168.2.104
2024-05-29T10:57:40 [I|app|99a24a09] Rendered text template (Duration: 0.0ms | Allocations: 1)
2024-05-29T10:57:40 [I|app|99a24a09] Completed 404 Not Found in 13ms (Views: 0.5ms | ActiveRecord: 6.1ms | Allocations: 2161)
- if you see those logs and you have discovered the machine before:
- get the mac of that machine and find out if theres some pxe config left in
cd /var/lib/tftpboot/pxelinux.cfg/(there should be a file/folder named after the machines mac to provide hardlink)
- if thats not the case you most likely have altered the pxe presets that is used by the os in foreman, or you have deleted activation key that was used by a previously provisioned machine
if theres a file under /var/lib/tftpboot/pxelinux.cfg/ named aftern the mac adress of the machine that fails tftp booting:
- just delete that file/folder
another reason is that your smartproxy is not correctly configured.
if you disable it and still encounter this error, it also means that its not dns/network related if you get logs trough foreman production logs i guess